edisgo.network package¶
edisgo.network.components module¶
- class edisgo.network.components.BasicComponent(**kwargs)[source]¶
Bases:
ABCGeneric component
Can be initialized with EDisGo object or Topology object. In case of Topology object component time series attributes currently will raise an error.
- property id¶
Unique identifier of component as used in component dataframes in
Topology.- Returns
Unique identifier of component.
- Return type
- property voltage_level¶
Voltage level the component is connected to (‘mv’ or ‘lv’).
- Returns
Voltage level. Returns ‘lv’ if component connected to the low voltage and ‘mv’ if component is connected to the medium voltage.
- Return type
- abstract property grid¶
Grid component is in.
- Returns
Grid component is in.
- Return type
Grid
- class edisgo.network.components.Component(**kwargs)[source]¶
Bases:
BasicComponentGeneric component for all components that can be considered nodes, e.g. generators and loads.
- property bus¶
Bus component is connected to.
- property grid¶
Grid the component is in.
- Returns
Grid object the component is in.
- Return type
Grid
- property geom¶
Geo location of component.
- Return type
- class edisgo.network.components.Load(**kwargs)[source]¶
Bases:
ComponentLoad object
- property p_set¶
Peak load in MW.
- property annual_consumption¶
Annual consumption of load in MWh.
- property sector¶
Sector load is associated with.
The sector is e.g. used to assign load time series to a load using the demandlib. The following four sectors are considered: ‘agricultural’, ‘retail’, ‘residential’, ‘industrial’.
- property active_power_timeseries¶
Active power time series of load in MW.
- Returns
Active power time series of load in MW.
- Return type
- property reactive_power_timeseries¶
Reactive power time series of load in Mvar.
- Returns
Reactive power time series of load in Mvar.
- Return type
- class edisgo.network.components.Generator(**kwargs)[source]¶
Bases:
ComponentGenerator object
- property nominal_power¶
Nominal power of generator in MW.
- property type¶
Technology type of generator (e.g. ‘solar’).
- property subtype¶
Technology subtype of generator (e.g. ‘solar_roof_mounted’).
- property active_power_timeseries¶
Active power time series of generator in MW.
- Returns
Active power time series of generator in MW.
- Return type
- property reactive_power_timeseries¶
Reactive power time series of generator in Mvar.
- Returns
Reactive power time series of generator in Mvar.
- Return type
- class edisgo.network.components.Storage(**kwargs)[source]¶
Bases:
ComponentStorage object
- property nominal_power¶
Nominal power of storage unit in MW.
- property active_power_timeseries¶
Active power time series of storage unit in MW.
- Returns
Active power time series of storage unit in MW.
- Return type
- property reactive_power_timeseries¶
Reactive power time series of storage unit in Mvar.
- Returns
Reactive power time series of storage unit in Mvar.
- Return type
- class edisgo.network.components.Switch(**kwargs)[source]¶
Bases:
BasicComponentSwitch object
Switches are for example medium voltage disconnecting points (points where MV rings are split under normal operation conditions). They are represented as branches and can have two states: ‘open’ or ‘closed’. When the switch is open the branch it is represented by connects some bus and the bus specified in bus_open. When it is closed bus bus_open is substitued by the bus specified in bus_closed.
- property type¶
Type of switch.
So far edisgo only considers switch disconnectors.
- property bus_open¶
Bus ID of bus the switch is ‘connected’ to when state is ‘open’.
As switches are represented as branches they connect two buses. bus_open specifies the bus the branch is connected to in the open state.
- Returns
Bus in ‘open’ state.
- Return type
- property bus_closed¶
Bus ID of bus the switch is ‘connected’ to when state is ‘closed’.
As switches are represented as branches they connect two buses. bus_closed specifies the bus the branch is connected to in the closed state.
- Returns
Bus in ‘closed’ state.
- Return type
- property state¶
State of switch (open or closed).
- Returns
State of switch: ‘open’ or ‘closed’.
- Return type
- property branch¶
Branch the switch is represented by.
- Returns
Branch the switch is represented by.
- Return type
- property grid¶
Grid switch is in.
- Returns
Grid switch is in.
- Return type
Grid
- class edisgo.network.components.PotentialChargingParks(**kwargs)[source]¶
Bases:
BasicComponent- property voltage_level¶
Voltage level the component is connected to (‘mv’ or ‘lv’).
- Returns
Voltage level. Returns ‘lv’ if component connected to the low voltage and ‘mv’ if component is connected to the medium voltage.
- Return type
- property grid¶
Grid component is in.
- Returns
Grid component is in.
- Return type
Grid
- property ags¶
8-digit AGS (Amtlicher Gemeindeschlüssel, eng. Community Identification Number) number the potential charging park is in. Number is given as
intand leading zeros are therefore missing.- Returns
AGS number
- Return type
- property use_case¶
Charging use case (home, work, public or hpc) of the potential charging park.
- Returns
Charging use case
- Return type
- property designated_charging_point_capacity¶
Total gross designated charging park capacity.
This is not necessarily equal to the connection rating.
- Returns
Total gross designated charging park capacity
- Return type
- property user_centric_weight¶
User centric weight of the potential charging park determined by SimBEV.
- Returns
User centric weight
- Return type
- property geometry¶
Location of the potential charging park as Shapely Point object.
- Returns
Location of the potential charging park.
- Return type
- property nearest_substation¶
Determines the nearest LV Grid, substation and distance.
- property edisgo_id¶
- property charging_processes_df¶
Determines designated charging processes for the potential charging park.
- Returns
DataFrame with AGS, car ID, trip destination, charging use case (private or public), netto charging capacity, charging demand, charge start, charge end, potential charging park ID and charging point ID.
- Return type
- property grid_connection_capacity¶
- property within_grid¶
Determines if the potential charging park is located within the grid district.
edisgo.network.electromobility module¶
- class edisgo.network.electromobility.Electromobility(**kwargs)[source]¶
Bases:
objectData container for all electromobility data.
This class holds data on charging processes (how long cars are parking at a charging station, how much they need to charge, etc.) necessary to apply different charging strategies, as well as information on potential charging sites and integrated charging parks.
- property charging_processes_df¶
DataFrame with all SimBEV charging processes.
- Returns
DataFrame with AGS, car ID, trip destination, charging use case, netto charging capacity, charging demand, charge start, charge end, grid connection point and charging point ID. The columns are:
- agsint
8-digit AGS (Amtlicher Gemeindeschlüssel, eng. Community Identification Number). Leading zeros are missing.
- car_idint
Car ID to differentiate charging processes from different cars.
- destinationstr
SimBEV driving destination.
- use_casestr
SimBEV use case. Can be “hpc”, “home”, “public” or “work”.
- nominal_charging_capacity_kWfloat
Vehicle charging capacity in kW.
- grid_charging_capacity_kWfloat
Grid-sided charging capacity including charging infrastructure losses in kW.
- chargingdemand_kWhfloat
Charging demand in kWh.
- park_time_timestepsint
Number of parking time steps.
- park_start_timestepsint
Time step the parking event starts.
- park_end_timestepsint
Time step the parking event ends.
- charging_park_idint
Designated charging park ID from potential_charging_parks_gdf. Is NaN if the charging demand is not yet distributed.
- charging_point_idint
Designated charging point ID. Is used to differentiate between multiple charging points at one charging park.
- Return type
- property potential_charging_parks_gdf¶
GeoDataFrame with all TracBEV potential charging parks.
- Returns
GeoDataFrame with ID as index, AGS, charging use case (home, work, public or hpc), user centric weight and geometry. Columns are:
- indexint
Charging park ID.
- use_casestr
TracBEV use case. Can be “hpc”, “home”, “public” or “work”.
- user_centric_weightflaot
User centric weight used in distribution of charging demand. Weight is determined by TracBEV but normalized from 0 .. 1.
- geometryGeoSeries
Geolocation of charging parks.
- Return type
- property potential_charging_parks¶
Potential charging parks within the AGS.
- Returns
List of potential charging parks within the AGS.
- Return type
list(
PotentialChargingParks)
- property simbev_config_df¶
Dict with all SimBEV config data.
- Returns
DataFrame with used regio type, charging point efficiency, stepsize in minutes, start date, end date, minimum SoC for hpc, grid timeseries setting, grid timeseries by use case setting and the number of simulated days. Columns are:
- regio_typestr
RegioStaR 7 ID used in SimBEV.
- eta_cpfloat or int
Charging point efficiency used in SimBEV.
- stepsizeint
Stepsize in minutes the driving profile is simulated for in SimBEV.
- start_datedatetime64
Start date of the SimBEV simulation.
- end_datedatetime64
End date of the SimBEV simulation.
- soc_minfloat
Minimum SoC when a HPC event is initialized in SimBEV.
- grid_timeseriesbool
Setting whether a grid timeseries is generated within the SimBEV simulation.
- grid_timeseries_by_usecasebool
Setting whether a grid timeseries by use case is generated within the SimBEV simulation.
- daysint
Timedelta between the end_date and start_date in days.
- Return type
- property integrated_charging_parks_df¶
Mapping DataFrame to map the charging park ID to the internal eDisGo ID.
The eDisGo ID is determined when integrating components using
add_component()orintegrate_component_based_on_geolocation()method.- Returns
Mapping DataFrame to map the charging park ID to the internal eDisGo ID.
- Return type
- property simulated_days¶
Number of simulated days in SimBEV.
- Returns
Number of simulated days
- Return type
- property eta_charging_points¶
Charging point efficiency.
- Returns
Charging point efficiency in p.u..
- Return type
- property flexibility_bands¶
Dictionary with flexibility bands (lower and upper energy band as well as upper power band).
- Parameters
flex_dict (dict(str, pandas.DataFrame)) – Keys are ‘upper_power’, ‘lower_energy’ and ‘upper_energy’. Values are dataframes containing the corresponding band per each charging point. Columns of the dataframe are the charging point names as in
loads_df. Index is a time index.- Returns
See input parameter flex_dict for more information on the dictionary.
- Return type
dict(str, pandas.DataFrame)
- get_flexibility_bands(edisgo_obj, use_case)[source]¶
Method to determine flexibility bands (lower and upper energy band as well as upper power band).
Besides being returned by this function, flexibility bands are written to
flexibility_bands.- Parameters
- Returns
Keys are ‘upper_power’, ‘lower_energy’ and ‘upper_energy’. Values are dataframes containing the corresponding band for each charging point of the specified use case. Columns of the dataframe are the charging point names as in
loads_df. Index is a time index.- Return type
dict(str, pandas.DataFrame)
- to_csv(directory, attributes=None)[source]¶
Exports electromobility data to csv files.
The following attributes can be exported:
‘charging_processes_df’ : Attribute
charging_processes_dfis saved to charging_processes.csv.‘potential_charging_parks_gdf’ : Attribute
potential_charging_parks_gdfis saved to potential_charging_parks.csv.‘integrated_charging_parks_df’ : Attribute
integrated_charging_parks_dfis saved to integrated_charging_parks.csv.‘simbev_config_df’ : Attribute
simbev_config_dfis saved to simbev_config.csv.‘flexibility_bands’ : The three flexibility bands in attribute
flexibility_bandsare saved to flexibility_band_upper_power.csv, flexibility_band_lower_energy.csv, and flexibility_band_upper_energy.csv.
edisgo.network.grids module¶
- class edisgo.network.grids.Grid(**kwargs)[source]¶
Bases:
ABCDefines a basic grid in eDisGo.
- property id¶
ID of the grid.
- property edisgo_obj¶
EDisGo object the grid is stored in.
- property nominal_voltage¶
Nominal voltage of network in kV.
- property graph¶
Graph representation of the grid.
- Returns
Graph representation of the grid as networkx Ordered Graph, where lines are represented by edges in the graph, and buses and transformers are represented by nodes.
- Return type
- property geopandas¶
Returns components as geopandas.GeoDataFrames
Returns container with geopandas.GeoDataFrames containing all georeferenced components within the grid.
- Returns
Data container with GeoDataFrames containing all georeferenced components within the grid(s).
- Return type
- property station¶
DataFrame with form of buses_df with only grid’s station’s secondary side bus information.
- property generators_df¶
Connected generators within the network.
- Returns
Dataframe with all generators in topology. For more information on the dataframe see
generators_df.- Return type
- property generators¶
Connected generators within the network.
- Returns
List of generators within the network.
- Return type
list(
Generator)
- property loads_df¶
Connected loads within the network.
- Returns
Dataframe with all loads in topology. For more information on the dataframe see
loads_df.- Return type
- property loads¶
Connected loads within the network.
- Returns
List of loads within the network.
- Return type
list(
Load)
- property storage_units_df¶
Connected storage units within the network.
- Returns
Dataframe with all storage units in topology. For more information on the dataframe see
storage_units_df.- Return type
- property charging_points_df¶
Connected charging points within the network.
- Returns
Dataframe with all charging points in topology. For more information on the dataframe see
loads_df.- Return type
- property switch_disconnectors_df¶
Switch disconnectors in network.
Switch disconnectors are points where rings are split under normal operating conditions.
- Returns
Dataframe with all switch disconnectors in network. For more information on the dataframe see
switches_df.- Return type
- property switch_disconnectors¶
Switch disconnectors within the network.
- Returns
List of switch disconnectory within the network.
- Return type
list(
Switch)
- property lines_df¶
Lines within the network.
- Returns
Dataframe with all buses in topology. For more information on the dataframe see
lines_df.- Return type
- abstract property buses_df¶
Buses within the network.
- Returns
Dataframe with all buses in topology. For more information on the dataframe see
buses_df.- Return type
- property weather_cells¶
Weather cells in network.
- property peak_generation_capacity¶
Cumulative peak generation capacity of generators in the network in MW.
- Returns
Cumulative peak generation capacity of generators in the network in MW.
- Return type
- property peak_generation_capacity_per_technology¶
Cumulative peak generation capacity of generators in the network per technology type in MW.
- Returns
Cumulative peak generation capacity of generators in the network per technology type in MW.
- Return type
- property p_set¶
Cumulative peak load of loads in the network in MW.
- Returns
Cumulative peak load of loads in the network in MW.
- Return type
- property p_set_per_sector¶
Cumulative peak load of loads in the network per sector in MW.
- Returns
Cumulative peak load of loads in the network per sector in MW.
- Return type
- class edisgo.network.grids.MVGrid(**kwargs)[source]¶
Bases:
GridDefines a medium voltage network in eDisGo.
- property lv_grids¶
Yields generator object with all underlying low voltage grids.
- property buses_df¶
Buses within the network.
- Returns
Dataframe with all buses in topology. For more information on the dataframe see
buses_df.- Return type
- property transformers_df¶
Transformers to overlaying network.
- Returns
Dataframe with all transformers to overlaying network. For more information on the dataframe see
transformers_df.- Return type
- class edisgo.network.grids.LVGrid(**kwargs)[source]¶
Bases:
GridDefines a low voltage network in eDisGo.
- property buses_df¶
Buses within the network.
- Returns
Dataframe with all buses in topology. For more information on the dataframe see
buses_df.- Return type
- property transformers_df¶
Transformers to overlaying network.
- Returns
Dataframe with all transformers to overlaying network. For more information on the dataframe see
transformers_df.- Return type
- draw(node_color='black', edge_color='black', colorbar=False, labels=False, filename=None)[source]¶
Draw LV network.
Currently, edge width is proportional to nominal apparent power of the line and node size is proportional to peak load of connected loads.
- Parameters
node_color (str or pandas.Series) – Color of the nodes (buses) of the grid. If provided as string all nodes will have that color. If provided as series, the index of the series must contain all buses in the LV grid and the corresponding values must be float values, that will be translated to the node color using a colormap, currently set to “Blues”. Default: “black”.
edge_color (str or pandas.Series) – Color of the edges (lines) of the grid. If provided as string all edges will have that color. If provided as series, the index of the series must contain all lines in the LV grid and the corresponding values must be float values, that will be translated to the edge color using a colormap, currently set to “inferno_r”. Default: “black”.
colorbar (bool) – If True, a colorbar is added to the plot for node and edge colors, in case these are sequences. Default: False.
labels (bool) – If True, displays bus names. As bus names are quite long, this is currently not very pretty. Default: False.
filename (str or None) – If a filename is provided, the plot is saved under that name but not displayed. If no filename is provided, the plot is only displayed. Default: None.
- property geopandas¶
Remove this as soon as LVGrids are georeferenced
- Type
TODO
edisgo.network.heat module¶
- class edisgo.network.heat.HeatPump(**kwargs)[source]¶
Bases:
objectData container for all heat pump data.
This class holds data on heat pump COP, heat demand time series, thermal storage data…
- property cop_df¶
DataFrame with COP time series of heat pumps.
- Parameters
df (pandas.DataFrame) – DataFrame with COP time series of heat pumps in p.u.. Index of the dataframe is a time index and should contain all time steps given in
timeindex. Column names are names of heat pumps as inloads_df.- Returns
DataFrame with COP time series of heat pumps in p.u.. For more information on the dataframe see input parameter df.
- Return type
- property heat_demand_df¶
DataFrame with heat demand time series of heat pumps.
- Parameters
df (pandas.DataFrame) – DataFrame with heat demand time series of heat pumps in MW. Index of the dataframe is a time index and should contain all time steps given in
timeindex. Column names are names of heat pumps as inloads_df.- Returns
DataFrame with heat demand time series of heat pumps in MW. For more information on the dataframe see input parameter df.
- Return type
- property thermal_storage_units_df¶
DataFrame with heat pump’s thermal storage information.
- Parameters
df (pandas.DataFrame) –
DataFrame with thermal storage information. Index of the dataframe are names of heat pumps as in
loads_df. Columns of the dataframe are:- capacityfloat
Thermal storage capacity in MWh.
- efficiencyfloat
Charging and discharging efficiency in p.u..
- state_of_charge_initialfloat
Initial state of charge in MWh.
- Returns
DataFrame with thermal storage information. For more information on the dataframe see input parameter df.
- Return type
- property building_ids_df¶
DataFrame with buildings served by each heat pump.
- Parameters
df (pandas.DataFrame) –
DataFrame with building IDs of buildings served by each heat pump. Index of the dataframe are names of heat pumps as in
loads_df. Columns of the dataframe are:- building_idslist(int)
List of building IDs.
- Returns
DataFrame with building IDs of buildings served by each heat pump. For more information on the dataframe see input parameter df.
- Return type
- set_cop(edisgo_object, ts_cop, heat_pump_names=None)[source]¶
Get COP time series for heat pumps.
Heat pumps need to already be integrated into the grid.
- Parameters
edisgo_object (
EDisGo) –ts_cop (str or pandas.DataFrame) –
Defines option used to set COP time series. Possible options are:
’oedb’
Not yet implemented! Weather cell specific hourly COP time series are obtained from the OpenEnergy DataBase for the weather year 2011. See
edisgo.io.timeseries_import.cop_oedb()for more information. Using information on which weather cell each heat pump is in, the weather cell specific time series are mapped to each heat pump.-
DataFrame with self-provided COP time series per heat pump. See
cop_dfon information on the required dataframe format.
heat_pump_names (list(str) or None) – Defines for which heat pumps to get COP time series for in case ts_cop is ‘oedb’. If None, all heat pumps in
loads_df(type is ‘heat_pump’) are used. Default: None.
- set_heat_demand(edisgo_object, ts_heat_demand, heat_pump_names=None)[source]¶
Get heat demand time series for buildings with heat pumps.
Heat pumps need to already be integrated into the grid.
- Parameters
edisgo_object (
EDisGo) –ts_heat_demand (str or pandas.DataFrame) –
Defines option used to set heat demand time series. Possible options are:
’oedb’
Not yet implemented! Heat demand time series are obtained from the OpenEnergy DataBase for the weather year 2011. See
edisgo.io.timeseries_import.heat_demand_oedb()for more information.-
DataFrame with self-provided heat demand time series per heat pump. See
heat_demand_dfon information on the required dataframe format.
heat_pump_names (list(str) or None) – Defines for which heat pumps to get heat demand time series for in case ts_heat_demand is ‘oedb’. If None, all heat pumps in
loads_df(type is ‘heat_pump’) are used. Default: None.
- reduce_memory(attr_to_reduce=None, to_type='float32')[source]¶
Reduces size of dataframes to save memory.
See
reduce_memoryfor more information.- Parameters
attr_to_reduce (list(str), optional) – List of attributes to reduce size for. Per default, the following attributes are reduced if they exist: cop_df, heat_demand_df.
to_type (str, optional) – Data type to convert time series data to. This is a tradeoff between precision and memory. Default: “float32”.
- to_csv(directory, reduce_memory=False, **kwargs)[source]¶
Exports heat pump data to csv files.
The following attributes are exported:
‘cop_df’
Attribute
cop_dfis saved to cop.csv.‘heat_demand_df’
Attribute
heat_demand_dfis saved to heat_demand.csv.‘thermal_storage_units_df’
Attribute
thermal_storage_units_dfis saved to thermal_storage_units.csv.‘building_ids_df’
Attribute
building_ids_dfis saved to building_ids.csv.
- Parameters
directory (str) – Path to save data to.
reduce_memory (bool, optional) – If True, size of dataframes is reduced using
reduce_memory. Optional parameters ofreduce_memorycan be passed as kwargs to this function. Default: False.kwargs – Kwargs may contain arguments of
reduce_memory.
edisgo.network.results module¶
- class edisgo.network.results.Results(edisgo_object)[source]¶
Bases:
objectPower flow analysis results management
Includes raw power flow analysis results, history of measures to increase the network’s hosting capacity and information about changes of equipment.
- property measures¶
List with measures conducted to increase network’s hosting capacity.
- Parameters
measure (str) – Measure to increase network’s hosting capacity. Possible options so far are ‘grid_expansion’, ‘storage_integration’, ‘curtailment’.
- Returns
A stack that details the history of measures to increase network’s hosting capacity. The last item refers to the latest measure. The key original refers to the state of the network topology as it was initially imported.
- Return type
- property pfa_p¶
Active power over components in MW from last power flow analysis.
The given active power for each line / transformer is the active power at the line ending / transformer side with the higher apparent power determined from active powers
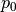 and
and
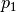 and reactive powers
and reactive powers 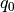 and at the
line endings / transformer sides:
and at the
line endings / transformer sides: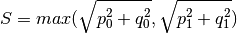
- Parameters
df (pandas.DataFrame) –
Results for active power over lines and transformers in MW from last power flow analysis. Index of the dataframe is a pandas.DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the dataframe are the representatives of the lines and stations included in the power flow analysis.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Results for active power over lines and transformers in MW from last power flow analysis. For more information on the dataframe see input parameter df.
- Return type
- property pfa_q¶
Active power over components in Mvar from last power flow analysis.
The given reactive power over each line / transformer is the reactive power at the line ending / transformer side with the higher apparent power determined from active powers
and
and reactive powers and 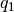 at the
line endings / transformer sides:
at the
line endings / transformer sides:- Parameters
df (pandas.DataFrame) –
Results for reactive power over lines and transformers in Mvar from last power flow analysis. Index of the dataframe is a pandas.DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the dataframe are the representatives of the lines and stations included in the power flow analysis.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Results for reactive power over lines and transformers in Mvar from last power flow analysis. For more information on the dataframe see input parameter df.
- Return type
- property v_res¶
Voltages at buses in p.u. from last power flow analysis.
- Parameters
df (pandas.DataFrame) –
Dataframe with voltages at buses in p.u. from last power flow analysis. Index of the dataframe is a pandas.DatetimeIndex indicating the time steps the power flow analysis was conducted for; columns of the dataframe are the bus names of all buses in the analyzed grids.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Dataframe with voltages at buses in p.u. from last power flow analysis. For more information on the dataframe see input parameter df.
- Return type
- property i_res¶
Current over components in kA from last power flow analysis.
- Parameters
df (pandas.DataFrame) –
Results for currents over lines and transformers in kA from last power flow analysis. Index of the dataframe is a pandas.DatetimeIndex indicating the time steps the power flow analysis was conducted for; columns of the dataframe are the representatives of the lines and stations included in the power flow analysis.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Results for current over lines and transformers in kA from last power flow analysis. For more information on the dataframe see input parameter df.
- Return type
- property s_res¶
Apparent power over components in MVA from last power flow analysis.
The given apparent power over each line / transformer is the apparent power at the line ending / transformer side with the higher apparent power determined from active powers
and
and reactive powers and at the
line endings / transformer sides:- Returns
Apparent power in MVA over lines and transformers. Index of the dataframe is a pandas.DatetimeIndex indicating the time steps the power flow analysis was conducted for; columns of the dataframe are the representatives of the lines and stations included in the power flow analysis.
- Return type
- property equipment_changes¶
Tracks changes to the grid topology.
When the grid is reinforced using
reinforceor new generators added usingimport_generators, new lines and/or transformers are added, lines split, etc. This is tracked in this attribute.- Parameters
df (pandas.DataFrame) –
Dataframe holding information on added, changed and removed lines and transformers. Index of the dataframe is in case of lines the name of the line, and in case of transformers the name of the grid the station is in (in case of MV/LV transformers the name of the LV grid and in case of HV/MV transformers the name of the MV grid). Columns are the following:
- equipmentstr
Type of new line or transformer as in
equipment_data.- changestr
Specifies if something was added, changed or removed.
- iteration_stepint
Grid reinforcement iteration step the change was conducted in. For changes conducted during grid integration of new generators the iteration step is set to 0.
- quantityint
Number of components added or removed. Only relevant for calculation of network expansion costs to keep track of how many new standard lines were added.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Dataframe holding information on added, changed and removed lines and transformers. For more information on the dataframe see input parameter df.
- Return type
- property grid_expansion_costs¶
Costs per expanded component in kEUR.
- Parameters
df (pandas.DataFrame) –
Costs per expanded line and transformer in kEUR. Index of the dataframe is the name of the expanded component as string. Columns are the following:
- typestr
Type of new line or transformer as in
equipment_data.- total_costsfloat
Costs of equipment in kEUR. For lines the line length and number of parallel lines is already included in the total costs.
- quantityint
For transformers quantity is always one, for lines it specifies the number of parallel lines.
- lengthfloat
Length of line or in case of parallel lines all lines in km.
- voltage_levelstr
Specifies voltage level the equipment is in (‘lv’, ‘mv’ or ‘mv/lv’).
Provide this if you want to set grid expansion costs. For retrieval of costs do not pass an argument.
- Returns
Costs per expanded line and transformer in kEUR. For more information on the dataframe see input parameter df.
- Return type
Notes
Network expansion measures are tracked in
equipment_changes. Resulting costs are calculated usinggrid_expansion_costs(). Total network expansion costs can be obtained through grid_expansion_costs.total_costs.sum().
- property grid_losses¶
Active and reactive network losses in MW and Mvar, respectively.
- Parameters
df (pandas.DataFrame) –
Results for active and reactive network losses in columns ‘p’ and ‘q’ and in MW and Mvar, respectively. Index is a pandas.DatetimeIndex.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Results for active and reactive network losses MW and Mvar, respectively. For more information on the dataframe see input parameter df.
- Return type
Notes
Grid losses are calculated as follows:
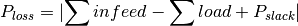
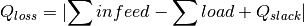
As the slack is placed at the station’s secondary side (if MV is included, it’s positioned at the HV/MV station’s secondary side and if a single LV grid is analysed it’s positioned at the LV station’s secondary side) losses do not include losses over the respective station’s transformers.
- property pfa_slack¶
Active and reactive power from slack in MW and Mvar, respectively.
In case the MV level is included in the power flow analysis, the slack is placed at the secondary side of the HV/MV station and gives the energy transferred to and taken from the HV network. In case a single LV network is analysed, the slack is positioned at the respective station’s secondary, in which case this gives the energy transferred to and taken from the overlying MV network.
- Parameters
df (pandas.DataFrame) –
Results for active and reactive power from the slack in MW and Mvar, respectively. Dataframe has the columns ‘p’, holding the active power results, and ‘q’, holding the reactive power results. Index is a pandas.DatetimeIndex.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Results for active and reactive power from the slack in MW and Mvar, respectively. For more information on the dataframe see input parameter df.
- Return type
- property pfa_v_mag_pu_seed¶
Voltages in p.u. from previous power flow analyses to be used as seed.
See
set_seed()for more information.- Parameters
df (pandas.DataFrame) –
Voltages at buses in p.u. from previous power flow analyses including the MV level. Index of the dataframe is a pandas.DatetimeIndex indicating the time steps previous power flow analyses were conducted for; columns of the dataframe are the representatives of the buses included in the power flow analyses.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Voltages at buses in p.u. from previous power flow analyses to be opionally used as seed in following power flow analyses. For more information on the dataframe see input parameter df.
- Return type
- property pfa_v_ang_seed¶
Voltages in p.u. from previous power flow analyses to be used as seed.
See
set_seed()for more information.- Parameters
df (pandas.DataFrame) –
Voltage angles at buses in radians from previous power flow analyses including the MV level. Index of the dataframe is a pandas.DatetimeIndex indicating the time steps previous power flow analyses were conducted for; columns of the dataframe are the representatives of the buses included in the power flow analyses.
Provide this if you want to set values. For retrieval of data do not pass an argument.
- Returns
Voltage angles at buses in radians from previous power flow analyses to be opionally used as seed in following power flow analyses. For more information on the dataframe see input parameter df.
- Return type
- property unresolved_issues¶
Lines and buses with remaining grid issues after network reinforcement.
In case overloading or voltage issues could not be solved after maximum number of iterations, network reinforcement is not aborted but network expansion costs are still calculated and unresolved issues listed here.
- Parameters
df (pandas.DataFrame) –
Dataframe containing remaining grid issues. Names of remaining critical lines, stations and buses are in the index of the dataframe. Columns depend on the equipment type. See
mv_line_load()for format of remaining overloading issues of lines,hv_mv_station_load()for format of remaining overloading issues of transformers, andmv_voltage_deviation()for format of remaining voltage issues.Provide this if you want to set unresolved_issues. For retrieval of data do not pass an argument.
- Returns
Dataframe with remaining grid issues. For more information on the dataframe see input parameter df.
- Return type
- reduce_memory(attr_to_reduce=None, to_type='float32')[source]¶
Reduces size of dataframes containing time series to save memory.
See
reduce_memoryfor more information.- Parameters
attr_to_reduce (list(str), optional) – List of attributes to reduce size for. Attributes need to be dataframes containing only time series. Possible options are: ‘pfa_p’, ‘pfa_q’, ‘v_res’, ‘i_res’, and ‘grid_losses’. Per default, all these attributes are reduced.
to_type (str, optional) – Data type to convert time series data to. This is a tradeoff between precision and memory. Default: “float32”.
Notes
Reducing the data type of the seeds for the power flow analysis,
pfa_v_mag_pu_seedandpfa_v_ang_seed, can lead to non-convergence of the power flow analysis, wherefore memory reduction is not provided for those attributes.
- equality_check(results_obj)[source]¶
Checks the equality of two results objects.
- Parameters
results_obj (:class:~.network.results.Results) – Contains the results of analyze function with default settings.
- Returns
True if equality check is successful, False otherwise.
- Return type
- to_csv(directory, parameters=None, reduce_memory=False, save_seed=False, **kwargs)[source]¶
Saves results to csv.
Saves power flow results and grid expansion results to separate directories. Which results are saved depends on what is specified in parameters. Per default, all attributes are saved.
Power flow results are saved to directory ‘powerflow_results’ and comprise the following, if not otherwise specified:
‘v_res’ : Attribute
v_resis saved to voltages_pu.csv.‘i_res’ : Attribute
i_resis saved to currents.csv.‘pfa_p’ : Attribute
pfa_pis saved to active_powers.csv.‘pfa_q’ : Attribute
pfa_qis saved to reactive_powers.csv.‘s_res’ : Attribute
s_resis saved to apparent_powers.csv.‘grid_losses’ : Attribute
grid_lossesis saved to grid_losses.csv.‘pfa_slack’ : Attribute
pfa_slackis saved to pfa_slack.csv.‘pfa_v_mag_pu_seed’ : Attribute
pfa_v_mag_pu_seedis saved to pfa_v_mag_pu_seed.csv, if save_seed is set to True.‘pfa_v_ang_seed’ : Attribute
pfa_v_ang_seedis saved to pfa_v_ang_seed.csv, if save_seed is set to True.
Grid expansion results are saved to directory ‘grid_expansion_results’ and comprise the following, if not otherwise specified:
grid_expansion_costs : Attribute
grid_expansion_costsis saved to grid_expansion_costs.csv.equipment_changes : Attribute
equipment_changesis saved to equipment_changes.csv.unresolved_issues : Attribute
unresolved_issuesis saved to unresolved_issues.csv.
- Parameters
directory (str) – Main directory to save the results in.
parameters (None or dict, optional) –
Specifies which results to save. By default this is set to None, in which case all results are saved. To only save certain results provide a dictionary. Possible keys are ‘powerflow_results’ and ‘grid_expansion_results’. Corresponding values must be lists with attributes to save or None to save all attributes. For example, with the first input only the power flow results i_res and v_res are saved, and with the second input all power flow results are saved.
{'powerflow_results': ['i_res', 'v_res']}
{'powerflow_results': None}
See function docstring for possible power flow and grid expansion results to save and under which file name they are saved.
reduce_memory (bool, optional) – If True, size of dataframes containing time series to save memory is reduced using
reduce_memory. Optional parameters ofreduce_memorycan be passed as kwargs to this function. Default: False.save_seed (bool, optional) – If True,
pfa_v_mag_pu_seedandpfa_v_ang_seedare as well saved as csv. As these are only relevant if calculations are not final, the default is False, in which case they are not saved.kwargs – Kwargs may contain optional arguments of
reduce_memory.
- from_csv(data_path, parameters=None, dtype=None, from_zip_archive=False)[source]¶
Restores results from csv files.
See
to_csv()for more information on which results can be saved and under which filename and directory they are stored.- Parameters
data_path (str) – Main data path results are saved in. Must be directory or zip archive.
parameters (None or dict, optional) – Specifies which results to restore. By default this is set to None, in which case all available results are restored. To only restore certain results provide a dictionary. Possible keys are ‘powerflow_results’ and ‘grid_expansion_results’. Corresponding values must be lists with attributes to restore or None to restore all available attributes. See function docstring parameters parameter in
to_csv()for more information.dtype (str, optional) – Numerical data type for data to be loaded from csv, e.g. “float32”. Per default this is None in which case data type is inferred.
from_zip_archive (bool, optional) – Set True if data is archived in a zip archive. Default: False.
edisgo.network.timeseries module¶
- class edisgo.network.timeseries.TimeSeries(**kwargs)[source]¶
Bases:
objectHolds component-specific active and reactive power time series.
All time series are fixed time series that in case of flexibilities result after application of a heuristic or optimisation. They can be used for power flow calculations.
Also holds any raw time series data that was used to generate component-specific time series in attribute time_series_raw. See
TimeSeriesRawfor more information.- Parameters
timeindex (pandas.DatetimeIndex, optional) – Can be used to define a time range for which to obtain the provided time series and run power flow analysis. Default: None.
- time_series_raw¶
Raw time series. See
TimeSeriesRawfor more information.- Type
- property is_worst_case: bool¶
Time series mode.
Is used to distinguish between normal time series analysis and worst-case analysis. Is determined by checking if the timindex starts before 1971 as the default for worst-case is 1970. Be mindful when creating your own worst-cases.
- Returns
Indicates if current time series is worst-case time series with different assumptions for mv and lv simultaneities.
- Return type
- property timeindex¶
Time index all time-dependent attributes are indexed by.
Is used as default time steps in e.g. power flow analysis.
- Parameters
ind (pandas.DatetimeIndex) – Time index all time-dependent attributes are indexed by.
- Returns
Time index all time-dependent attributes are indexed by.
- Return type
- property generators_active_power¶
Active power time series of generators in MW.
- Parameters
df (pandas.DataFrame) – Active power time series of all generators in topology in MW. Index of the dataframe is a time index and column names are names of generators.
- Returns
Active power time series of all generators in topology in MW for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- property generators_reactive_power¶
Reactive power time series of generators in MVA.
- Parameters
df (pandas.DataFrame) – Reactive power time series of all generators in topology in MVA. Index of the dataframe is a time index and column names are names of generators.
- Returns
Reactive power time series of all generators in topology in MVA for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- property loads_active_power¶
Active power time series of loads in MW.
- Parameters
df (pandas.DataFrame) – Active power time series of all loads in topology in MW. Index of the dataframe is a time index and column names are names of loads.
- Returns
Active power time series of all loads in topology in MW for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- property loads_reactive_power¶
Reactive power time series of loads in MVA.
- Parameters
df (pandas.DataFrame) – Reactive power time series of all loads in topology in MVA. Index of the dataframe is a time index and column names are names of loads.
- Returns
Reactive power time series of all loads in topology in MVA for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- charging_points_active_power(edisgo_object)[source]¶
Returns a subset of
loads_active_powercontaining only the time series of charging points.- Parameters
edisgo_object (
EDisGo) –- Returns
Pandas DataFrame with active power time series of charging points.
- Return type
- charging_points_reactive_power(edisgo_object)[source]¶
Returns a subset of
loads_reactive_powercontaining only the time series of charging points.- Parameters
edisgo_object (
EDisGo) –- Returns
Pandas DataFrame with reactive power time series of charging points.
- Return type
- property storage_units_active_power¶
Active power time series of storage units in MW.
- Parameters
df (pandas.DataFrame) – Active power time series of all storage units in topology in MW. Index of the dataframe is a time index and column names are names of storage units.
- Returns
Active power time series of all storage units in topology in MW for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- property storage_units_reactive_power¶
Reactive power time series of storage units in MVA.
- Parameters
df (pandas.DataFrame) – Reactive power time series of all storage units in topology in MVA. Index of the dataframe is a time index and column names are names of storage units.
- Returns
Reactive power time series of all storage units in topology in MVA for time steps given in
timeindex. For more information on the dataframe see input parameter df.- Return type
- reset()[source]¶
Resets all time series.
Active and reactive power time series of all loads, generators and storage units are deleted, as well as timeindex and everything stored in
time_series_raw.
- set_active_power_manual(edisgo_object, ts_generators=None, ts_loads=None, ts_storage_units=None)[source]¶
Sets given component active power time series.
If time series for a component were already set before, they are overwritten.
- Parameters
edisgo_object (
EDisGo) –ts_generators (pandas.DataFrame) – Active power time series in MW of generators. Index of the data frame is a datetime index. Columns contain generators names of generators to set time series for.
ts_loads (pandas.DataFrame) – Active power time series in MW of loads. Index of the data frame is a datetime index. Columns contain load names of loads to set time series for.
ts_storage_units (pandas.DataFrame) – Active power time series in MW of storage units. Index of the data frame is a datetime index. Columns contain storage unit names of storage units to set time series for.
- set_reactive_power_manual(edisgo_object, ts_generators=None, ts_loads=None, ts_storage_units=None)[source]¶
Sets given component reactive power time series.
If time series for a component were already set before, they are overwritten.
- Parameters
edisgo_object (
EDisGo) –ts_generators (pandas.DataFrame) – Reactive power time series in MVA of generators. Index of the data frame is a datetime index. Columns contain generators names of generators to set time series for.
ts_loads (pandas.DataFrame) – Reactive power time series in MVA of loads. Index of the data frame is a datetime index. Columns contain load names of loads to set time series for.
ts_storage_units (pandas.DataFrame) – Reactive power time series in MVA of storage units. Index of the data frame is a datetime index. Columns contain storage unit names of storage units to set time series for.
- set_worst_case(edisgo_object, cases, generators_names=None, loads_names=None, storage_units_names=None)[source]¶
Sets demand and feed-in of loads, generators and storage units for the specified worst cases.
Per default time series are set for all loads, generators and storage units in the network.
Possible worst cases are ‘load_case’ (heavy load flow case) and ‘feed-in_case’ (reverse power flow case). Each case is set up once for dimensioning of the MV grid (‘load_case_mv’/’feed-in_case_mv’) and once for the dimensioning of the LV grid (‘load_case_lv’/’feed-in_case_lv’), as different simultaneity factors are assumed for the different voltage levels.
Assumed simultaneity factors specified in the config section worst_case_scale_factor are used to generate active power demand or feed-in. For the reactive power behavior fixed cosphi is assumed. The power factors set in the config section reactive_power_factor and the power factor mode, defining whether components behave inductive or capacitive, given in the config section reactive_power_mode, are used.
Component specific information is given below:
Generators
Worst case feed-in time series are distinguished by technology (PV, wind and all other) and whether it is a load or feed-in case. In case of generator worst case time series it is not distinguished by whether it is used to analyse the MV or LV. However, both options are generated as it is distinguished in the case of loads. Worst case scaling factors for generators are specified in the config section worst_case_scale_factor through the parameters: ‘feed-in_case_feed-in_pv’, ‘feed-in_case_feed-in_wind’, ‘feed-in_case_feed-in_other’, ‘load_case_feed-in_pv’, load_case_feed-in_wind’, and ‘load_case_feed-in_other’.
For reactive power a fixed cosphi is assumed. A different reactive power factor is used for generators in the MV and generators in the LV. The reactive power factors for generators are specified in the config section reactive_power_factor through the parameters: ‘mv_gen’ and ‘lv_gen’.
Conventional loads
Worst case load time series are distinguished by whether it is a load or feed-in case and whether it used to analyse the MV or LV. Worst case scaling factors for conventional loads are specified in the config section worst_case_scale_factor through the parameters: ‘mv_feed-in_case_load’, ‘lv_feed-in_case_load’, ‘mv_load_case_load’, and ‘lv_load_case_load’.
For reactive power a fixed cosphi is assumed. A different reactive power factor is used for loads in the MV and loads in the LV. The reactive power factors for conventional loads are specified in the config section reactive_power_factor through the parameters: ‘mv_load’ and ‘lv_load’.
Charging points
Worst case demand time series are distinguished by use case (home charging, work charging, public (slow) charging and HPC), by whether it is a load or feed-in case and by whether it used to analyse the MV or LV. Worst case scaling factors for charging points are specified in the config section worst_case_scale_factor through the parameters: ‘mv_feed-in_case_cp_home’, ‘mv_feed-in_case_cp_work’, ‘mv_feed-in_case_cp_public’, and ‘mv_feed-in_case_cp_hpc’, ‘lv_feed-in_case_cp_home’, ‘lv_feed-in_case_cp_work’, ‘lv_feed-in_case_cp_public’, and ‘lv_feed-in_case_cp_hpc’, ‘mv_load-in_case_cp_home’, ‘mv_load-in_case_cp_work’, ‘mv_load-in_case_cp_public’, and ‘mv_load-in_case_cp_hpc’, ‘lv_load-in_case_cp_home’, ‘lv_load-in_case_cp_work’, ‘lv_load-in_case_cp_public’, and ‘lv_load-in_case_cp_hpc’.
For reactive power a fixed cosphi is assumed. A different reactive power factor is used for charging points in the MV and charging points in the LV. The reactive power factors for charging points are specified in the config section reactive_power_factor through the parameters: ‘mv_cp’ and ‘lv_cp’.
Heat pumps
Worst case demand time series are distinguished by whether it is a load or feed-in case and by whether it used to analyse the MV or LV. Worst case scaling factors for heat pumps are specified in the config section worst_case_scale_factor through the parameters: ‘mv_feed-in_case_hp’, ‘lv_feed-in_case_hp’, ‘mv_load_case_hp’, and ‘lv_load_case_hp’.
For reactive power a fixed cosphi is assumed. A different reactive power factor is used for heat pumps in the MV and heat pumps in the LV. The reactive power factors for heat pumps are specified in the config section reactive_power_factor through the parameters: ‘mv_hp’ and ‘lv_hp’.
Storage units
Worst case feed-in time series are distinguished by whether it is a load or feed-in case. In case of storage units worst case time series it is not distinguished by whether it is used to analyse the MV or LV. However, both options are generated as it is distinguished in the case of loads. Worst case scaling factors for storage units are specified in the config section worst_case_scale_factor through the parameters: ‘feed-in_case_storage’ and ‘load_case_storage’.
For reactive power a fixed cosphi is assumed. A different reactive power factor is used for storage units in the MV and storage units in the LV. The reactive power factors for storage units are specified in the config section reactive_power_factor through the parameters: ‘mv_storage’ and ‘lv_storage’.
- Parameters
edisgo_object (
EDisGo) –cases (list(str)) – List with worst-cases to generate time series for. Can be ‘feed-in_case’, ‘load_case’ or both.
generators_names (list(str)) – Defines for which generators to set worst case time series. If None, time series are set for all generators. Default: None.
loads_names (list(str)) – Defines for which loads to set worst case time series. If None, time series are set for all loads. Default: None.
storage_units_names (list(str)) – Defines for which storage units to set worst case time series. If None, time series are set for all storage units. Default: None.
Notes
Be careful, this function overwrites all previously set time series in the case that these are not worst case time series. If previously set time series are worst case time series is checked using
is_worst_case.Further, if this function is called for a component whose worst-case time series are already set, they are overwritten, even if previously set time series were set for a different worst-case.
Also be aware that loads for which type information is not set are handled as conventional loads.
- predefined_fluctuating_generators_by_technology(edisgo_object, ts_generators, generator_names=None)[source]¶
Set active power feed-in time series for fluctuating generators by technology.
In case time series are provided per technology and weather cell ID, active power feed-in time series are also set by technology and weather cell ID.
- Parameters
edisgo_object (
EDisGo) –ts_generators (str or pandas.DataFrame) –
Defines which technology-specific or technology and weather cell specific active power time series to use. Possible options are:
’oedb’
Technology and weather cell specific hourly feed-in time series are obtained from the OpenEnergy DataBase for the weather year 2011. See
edisgo.io.timeseries_import.import_feedin_timeseries()for more information.-
DataFrame with self-provided feed-in time series per technology or per technology and weather cell ID normalized to a nominal capacity of 1. In case time series are provided only by technology, columns of the DataFrame contain the technology type as string. In case time series are provided by technology and weather cell ID columns need to be a pandas.MultiIndex with the first level containing the technology as string and the second level the weather cell ID as integer. Index needs to be a pandas.DatetimeIndex.
When importing a ding0 grid and/or using predefined scenarios of the future generator park, each generator has an assigned weather cell ID that identifies the weather data cell from the weather data set used in the research project open_eGo to determine feed-in profiles. The weather cell ID can be retrieved from column weather_cell_id in
generators_dfand could be overwritten to use own weather cells.
generator_names (list(str)) – Defines for which fluctuating generators to use technology-specific time series. If None, all generators technology (and weather cell) specific time series are provided for are used. In case the time series are retrieved from the oedb, all solar and wind generators are used. Default: None.
- predefined_dispatchable_generators_by_technology(edisgo_object, ts_generators, generator_names=None)[source]¶
Set active power feed-in time series for dispatchable generators by technology.
- Parameters
edisgo_object (
EDisGo) –ts_generators (pandas.DataFrame) – DataFrame with self-provided active power time series of each type of dispatchable generator normalized to a nominal capacity of 1. Columns contain the technology type as string, e.g. ‘gas’, ‘coal’. Use ‘other’ if you don’t want to explicitly provide a time series for every possible technology. In the current grid existing generator technologies can be retrieved from column type in
generators_df. Index needs to be a pandas.DatetimeIndex.generator_names (list(str)) – Defines for which dispatchable generators to use technology-specific time series. If None, all dispatchable generators technology-specific time series are provided for are used. In case ts_generators contains a column ‘other’, all dispatchable generators in the network (i.e. all but solar and wind generators) are used.
- predefined_conventional_loads_by_sector(edisgo_object, ts_loads, load_names=None)[source]¶
Set active power demand time series for conventional loads by sector.
- Parameters
edisgo_object (
EDisGo) –ts_loads (str or pandas.DataFrame) –
Defines which sector-specific active power time series to use. Possible options are:
’demandlib’
-
DataFrame with load time series per sector normalized to an annual consumption of 1. Index needs to be a pandas.DatetimeIndex. Columns contain the sector as string. In the current grid existing load types can be retrieved from column sector in
loads_df(make sure to select type ‘conventional_load’). In ding0 grid the differentiated sectors are ‘residential’, ‘retail’, ‘industrial’, and ‘agricultural’.
load_names (list(str)) – Defines for which conventional loads to use sector-specific time series. If None, all loads of sectors for which sector-specific time series are provided are used. In case the demandlib is used, all loads of sectors ‘residential’, ‘retail’, ‘industrial’, and ‘agricultural’ are used.
- predefined_charging_points_by_use_case(edisgo_object, ts_loads, load_names=None)[source]¶
Set active power demand time series for charging points by their use case.
- Parameters
edisgo_object (
EDisGo) –ts_loads (pandas.DataFrame) – DataFrame with self-provided load time series per use case normalized to a nominal power of the charging point of 1. Index needs to be a pandas.DatetimeIndex. Columns contain the use case as string. In the current grid existing use case types can be retrieved from column sector in
loads_df(make sure to select type ‘charging_point’). When using charging point input from SimBEV the differentiated use cases are ‘home’, ‘work’, ‘public’ and ‘hpc’.load_names (list(str)) – Defines for which charging points to use use-case-specific time series. If None, all charging points of use cases for which use-case-specific time series are provided are used.
- fixed_cosphi(edisgo_object, generators_parametrisation=None, loads_parametrisation=None, storage_units_parametrisation=None)[source]¶
Sets reactive power of specified components assuming a fixed power factor.
Overwrites reactive power time series in case they already exist.
- Parameters
generators_parametrisation (str or pandas.DataFrame or None) –
Sets fixed cosphi parameters for generators. Possible options are:
’default’
Default configuration is used for all generators in the grid. To this end, the power factors set in the config section reactive_power_factor and the power factor mode, defining whether components behave inductive or capacitive, given in the config section reactive_power_mode, are used.
-
DataFrame with fix cosphi parametrisation for specified generators. Columns are:
- ’components’list(str)
List with generators to apply parametrisation for.
- ’mode’str
Defines whether generators behave inductive or capacitive. Possible options are ‘inductive’, ‘capacitive’ or ‘default’. In case of ‘default’, configuration from config section reactive_power_mode is used.
- ’power_factor’float or str
Defines the fixed cosphi power factor. The power factor can either be directly provided as float or it can be set to ‘default’, in which case configuration from config section reactive_power_factor is used.
Index of the dataframe is ignored.
None
No reactive power time series are set.
Default: None.
loads_parametrisation (str or pandas.DataFrame or None) – Sets fixed cosphi parameters for loads. The same options as for parameter generators_parametrisation apply.
storage_units_parametrisation (str or pandas.DataFrame or None) – Sets fixed cosphi parameters for storage units. The same options as for parameter generators_parametrisation apply.
Notes
This function requires active power time series to be previously set.
- property residual_load¶
Returns residual load in network.
Residual load for each time step is calculated from total load minus total generation minus storage active power (discharge is positive). A positive residual load represents a load case while a negative residual load here represents a feed-in case. Grid losses are not considered.
- Returns
Series with residual load in MW.
- Return type
- property timesteps_load_feedin_case¶
Contains residual load and information on feed-in and load case.
Residual load is calculated from total (load - generation) in the network. Grid losses are not considered.
Feed-in and load case are identified based on the generation, load and storage time series and defined as follows:
Load case: positive (load - generation - storage) at HV/MV substation
Feed-in case: negative (load - generation - storage) at HV/MV substation
- Returns
Series with information on whether time step is handled as load case (‘load_case’) or feed-in case (‘feed-in_case’) for each time step in
timeindex.- Return type
- reduce_memory(attr_to_reduce=None, to_type='float32', time_series_raw=True, **kwargs)[source]¶
Reduces size of dataframes to save memory.
See
reduce_memoryfor more information.- Parameters
attr_to_reduce (list(str), optional) – List of attributes to reduce size for. Per default, all active and reactive power time series of generators, loads, and storage units are reduced.
to_type (str, optional) – Data type to convert time series data to. This is a tradeoff between precision and memory. Default: “float32”.
time_series_raw (bool, optional) – If True raw time series data in
time_series_rawis reduced as well. Default: True.attr_to_reduce_raw (list(str), optional) – List of attributes in
TimeSeriesRawto reduce size for. Seereduce_memoryfor default.
- to_csv(directory, reduce_memory=False, time_series_raw=False, **kwargs)[source]¶
Saves component time series to csv.
Saves the following time series to csv files with the same file name (if the time series dataframe is not empty):
loads_active_power and loads_reactive_power
generators_active_power and generators_reactive_power
storage_units_active_power and storage_units_reactive_power
If parameter time_series_raw is set to True, raw time series data is saved to csv as well. See
to_csvfor more information.- Parameters
directory (str) – Directory to save time series in.
reduce_memory (bool, optional) – If True, size of dataframes is reduced using
reduce_memory. Optional parameters ofreduce_memorycan be passed as kwargs to this function. Default: False.time_series_raw (bool, optional) – If True raw time series data in
time_series_rawis saved to csv as well. Per default all raw time series data is then stored in a subdirectory of the specified directory called “time_series_raw”. Further, if reduce_memory is set to True, raw time series data is reduced as well. To change this default behavior please callto_csvseparately. Default: False.kwargs – Kwargs may contain arguments of
reduce_memory.
- from_csv(data_path, dtype=None, time_series_raw=False, from_zip_archive=False, **kwargs)[source]¶
Restores time series from csv files.
See
to_csv()for more information on which time series can be saved and thus restored.- Parameters
data_path (str) – Data path time series are saved in. Must be a directory or zip archive.
dtype (str, optional) – Numerical data type for data to be loaded from csv. E.g. “float32”. Default: None.
time_series_raw (bool, optional) – If True raw time series data is as well read in (see
from_csvfor further information). Directory data is restored from can be specified through kwargs. Default: False.from_zip_archive (bool, optional) – Set True if data is archived in a zip archive. Default: False.
directory_raw (str, optional) – Directory to read raw time series data from. Per default this is a subdirectory of the specified directory called “time_series_raw”.
- check_integrity()[source]¶
Check for NaN, duplicated indices or columns and if time series is empty.
- drop_component_time_series(df_name, comp_names)[source]¶
Drops component time series if they exist.
- Parameters
df_name (str) – Name of attribute of given object holding the dataframe to remove columns from. Can e.g. be “generators_active_power” if time series should be removed from
generators_active_power.comp_names (str or list(str)) – Names of components to drop.
- add_component_time_series(df_name, ts_new)[source]¶
Add component time series by concatenating existing and provided dataframe.
Possibly already component time series are dropped before appending newly provided time series using
drop_component_time_series.- Parameters
df_name (str) – Name of attribute of given object holding the dataframe to add columns to. Can e.g. be “generators_active_power” if time series should be added to
generators_active_power.ts_new (pandas.DataFrame) – Dataframe with new time series to add to existing time series dataframe.
- resample_timeseries(method='ffill', freq='15min')[source]¶
Resamples all generator, load and storage time series to a desired resolution.
See
resample_timeseriesfor more information.- Parameters
method (str, optional) – See
resample_timeseriesfor more information.freq (str, optional) – See
resample_timeseriesfor more information.
- class edisgo.network.timeseries.TimeSeriesRaw[source]¶
Bases:
objectHolds raw time series data, e.g. sector-specific demand and standing times of EV.
Normalised time series are e.g. sector-specific demand time series or technology-specific feed-in time series. Time series needed for flexibilities are e.g. heat time series or curtailment time series.
- q_control¶
Dataframe with information on applied reactive power control or in case of conventional loads assumed reactive power behavior. Index of the dataframe are the component names as in index of
generators_df,loads_df, andstorage_units_df. Columns are “type” with the type of Q-control applied (can be “fixed_cosphi”, “cosphi(P)”, or “Q(V)”), “power_factor” with the (maximum) power factor, “q_sign” giving the sign of the reactive power (only applicable to “fixed_cosphi”), “parametrisation” with the parametrisation of the respective Q-control (only applicable to “cosphi(P)” and “Q(V)”).- Type
- fluctuating_generators_active_power_by_technology¶
DataFrame with feed-in time series per technology or technology and weather cell ID normalized to a nominal capacity of 1. Columns can either just contain the technology type as string or be a pandas.MultiIndex with the first level containing the technology as string and the second level the weather cell ID as integer. Index is a pandas.DatetimeIndex.
- Type
- dispatchable_generators_active_power_by_technology¶
DataFrame with feed-in time series per technology normalized to a nominal capacity of 1. Columns contain the technology type as string. Index is a pandas.DatetimeIndex.
- Type
- conventional_loads_active_power_by_sector¶
DataFrame with load time series of each type of conventional load normalized to an annual consumption of 1. Index needs to be a pandas.DatetimeIndex. Columns represent load type. In ding0 grids the differentiated sectors are ‘residential’, ‘retail’, ‘industrial’, and ‘agricultural’.
- Type
- charging_points_active_power_by_use_case¶
DataFrame with charging demand time series per use case normalized to a nominal capacity of 1. Columns contain the use case as string. Index is a pandas.DatetimeIndex.
- Type
- reduce_memory(attr_to_reduce=None, to_type='float32')[source]¶
Reduces size of dataframes to save memory.
See
reduce_memoryfor more information.- Parameters
attr_to_reduce (list(str), optional) – List of attributes to reduce size for. Attributes need to be dataframes containing only time series. Per default the following attributes are reduced if they exist: q_control, fluctuating_generators_active_power_by_technology, dispatchable_generators_active_power_by_technology, conventional_loads_active_power_by_sector, charging_points_active_power_by_use_case.
to_type (str, optional) – Data type to convert time series data to. This is a tradeoff between precision and memory. Default: “float32”.
- to_csv(directory, reduce_memory=False, **kwargs)[source]¶
Saves time series to csv.
Saves all attributes that are set to csv files with the same file name. See class definition for possible attributes.
- Parameters
directory (str) – Directory to save time series in.
reduce_memory (bool, optional) – If True, size of dataframes is reduced using
reduce_memory. Optional parameters ofreduce_memorycan be passed as kwargs to this function. Default: False.kwargs – Kwargs may contain optional arguments of
reduce_memory.
edisgo.network.topology module¶
- class edisgo.network.topology.Topology(**kwargs)[source]¶
Bases:
objectContainer for all grid topology data of a single MV grid.
Data may as well include grid topology data of underlying LV grids.
- Parameters
config (None or
Config) – Provide your configurations if you want to load self-provided equipment data. Path to csv files containing the technical data is set in config_system.cfg in sections system_dirs and equipment. The default is None in which case the equipment data provided by eDisGo is used.
- property loads_df¶
Dataframe with all loads in MV network and underlying LV grids.
- Parameters
df (pandas.DataFrame) –
Dataframe with all loads (incl. charging points, heat pumps, etc.) in MV network and underlying LV grids. Index of the dataframe are load names as string. Columns of the dataframe are:
- busstr
Identifier of bus load is connected to.
- p_setfloat
Peak load or nominal capacity in MW.
- typestr
Type of load, e.g. ‘conventional_load’, ‘charging_point’ or ‘heat_pump’. This information is for example currently necessary when setting up a worst case analysis, as different types of loads are treated differently.
- annual_consumptionfloat
Annual consumption in MWh.
- sectorstr
Further specifies type of load.
In case of conventional loads this attribute is used if demandlib is used to generate sector-specific time series (see function
predefined_conventional_loads_by_sector). It is further used when new generators are integrated into the grid, as e.g. smaller PV rooftop generators are most likely to be located in a household (see functionconnect_to_lv). The sector needs to either be ‘agricultural’, ‘industrial’, ‘residential’ or ‘retail’.In case of charging points this attribute is used to define the charging point use case (‘home’, ‘work’, ‘public’ or ‘hpc’) to determine whether a charging process can be flexibilised, as it is assumed that only charging processes at private charging points (‘home’ and ‘work’) can be flexibilised (see function
charging_strategy). It is further used when charging points are integrated into the grid, as e.g. ‘home’ charging points are allocated to a household (see functionconnect_to_lv).In case of heat pumps it is used when heat pumps are integrated into the grid, as e.g. heat pumps for individual heating are allocated to an existing load (see function
connect_to_lv). The sector needs to either be ‘individual_heating’ or ‘district_heating’.
- Returns
Dataframe with all loads in MV network and underlying LV grids. For more information on the dataframe see input parameter df.
- Return type
- property generators_df¶
Dataframe with all generators in MV network and underlying LV grids.
- Parameters
df (pandas.DataFrame) –
Dataframe with all generators in MV network and underlying LV grids. Index of the dataframe are generator names as string. Columns of the dataframe are:
- busstr
Identifier of bus generator is connected to.
- p_nomfloat
Nominal power in MW.
- typestr
Type of generator, e.g. ‘solar’, ‘run_of_river’, etc. Is used in case generator type specific time series are provided.
- controlstr
Control type of generator used for power flow analysis. In MV and LV grids usually ‘PQ’.
- weather_cell_idint
ID of weather cell, that identifies the weather data cell from the weather data set used in the research project open_eGo to determine feed-in profiles of wind and solar generators. Only required when time series of wind and solar generators are assigned using precalculated time series from the OpenEnergy DataBase.
- subtypestr
Further specification of type, e.g. ‘solar_roof_mounted’. Currently not required for any functionality.
- Returns
Dataframe with all generators in MV network and underlying LV grids. For more information on the dataframe see input parameter df.
- Return type
- property storage_units_df¶
Dataframe with all storage units in MV grid and underlying LV grids.
- Parameters
df (pandas.DataFrame) –
Dataframe with all storage units in MV grid and underlying LV grids. Index of the dataframe are storage names as string. Columns of the dataframe are:
- busstr
Identifier of bus storage unit is connected to.
- controlstr
Control type of storage unit used for power flow analysis, usually ‘PQ’.
- p_nomfloat
Nominal power in MW.
- Returns
Dataframe with all storage units in MV network and underlying LV grids. For more information on the dataframe see input parameter df.
- Return type
- property transformers_df¶
Dataframe with all MV/LV transformers.
- Parameters
df (pandas.DataFrame) –
Dataframe with all MV/LV transformers. Index of the dataframe are transformer names as string. Columns of the dataframe are:
- bus0str
Identifier of bus at the transformer’s primary (MV) side.
- bus1str
Identifier of bus at the transformer’s secondary (LV) side.
- x_pufloat
Per unit series reactance.
- r_pufloat
Per unit series resistance.
- s_nomfloat
Nominal apparent power in MW.
- type_infostr
Type of transformer.
- Returns
Dataframe with all MV/LV transformers. For more information on the dataframe see input parameter df.
- Return type
- property transformers_hvmv_df¶
Dataframe with all HV/MV transformers.
- Parameters
df (pandas.DataFrame) – Dataframe with all HV/MV transformers, with the same format as
transformers_df.- Returns
Dataframe with all HV/MV transformers. For more information on format see
transformers_df.- Return type
- property lines_df¶
Dataframe with all lines in MV network and underlying LV grids.
- Parameters
df (pandas.DataFrame) –
Dataframe with all lines in MV network and underlying LV grids. Index of the dataframe are line names as string. Columns of the dataframe are:
- bus0str
Identifier of first bus to which line is attached.
- bus1str
Identifier of second bus to which line is attached.
- lengthfloat
Line length in km.
- xfloat
Reactance of line (or in case of multiple parallel lines total reactance of lines) in Ohm.
- rfloat
Resistance of line (or in case of multiple parallel lines total resistance of lines) in Ohm.
- s_nomfloat
Apparent power which can pass through the line (or in case of multiple parallel lines total apparent power which can pass through the lines) in MVA.
- num_parallelint
Number of parallel lines.
- type_infostr
Type of line as e.g. given in equipment_data.
- kindstr
Specifies whether line is a cable (‘cable’) or overhead line (‘line’).
- Returns
Dataframe with all lines in MV network and underlying LV grids. For more information on the dataframe see input parameter df.
- Return type
- property buses_df¶
Dataframe with all buses in MV network and underlying LV grids.
- Parameters
df (pandas.DataFrame) –
Dataframe with all buses in MV network and underlying LV grids. Index of the dataframe are bus names as strings. Columns of the dataframe are:
- v_nomfloat
Nominal voltage in kV.
- xfloat
x-coordinate (longitude) of geolocation.
- yfloat
y-coordinate (latitude) of geolocation.
- mv_grid_idint
ID of MV grid the bus is in.
- lv_grid_idint
ID of LV grid the bus is in. In case of MV buses this is NaN.
- in_buildingbool
Signifies whether a bus is inside a building, in which case only components belonging to this house connection can be connected to it.
- Returns
Dataframe with all buses in MV network and underlying LV grids.
- Return type
- property switches_df¶
Dataframe with all switches in MV network and underlying LV grids.
Switches are implemented as branches that, when they are closed, are connected to a bus (bus_closed) such that there is a closed ring, and when they are open, connected to a virtual bus (bus_open), such that there is no closed ring. Once the ring is closed, the virtual is a single bus that is not connected to the rest of the grid.
- Parameters
df (pandas.DataFrame) –
Dataframe with all switches in MV network and underlying LV grids. Index of the dataframe are switch names as string. Columns of the dataframe are:
- bus_openstr
Identifier of bus the switch branch is connected to when the switch is open.
- bus_closedstr
Identifier of bus the switch branch is connected to when the switch is closed.
- branchstr
Identifier of branch that represents the switch.
- typestr
Type of switch, e.g. switch disconnector.
- Returns
Dataframe with all switches in MV network and underlying LV grids. For more information on the dataframe see input parameter df.
- Return type
- property charging_points_df¶
Returns a subset of
loads_dfcontaining only charging points.- Parameters
type (str) – Load type. Default: “charging_point”
- Returns
Pandas DataFrame with all loads of the given type.
- Return type
- property mv_grid¶
Medium voltage network.
The medium voltage network object only contains components (lines, generators, etc.) that are in or connected to the MV grid and does not include any components of the underlying LV grids (also not MV/LV transformers).
- property lv_grids¶
Yields generator object with all low voltage grids in network.
- property grid_district¶
Dictionary with MV grid district information.
- Parameters
grid_district (dict) –
Dictionary with the following MV grid district information:
- ’population’int
Number of inhabitants in grid district.
- ’geom’shapely.MultiPolygon
Geometry of MV grid district as (Multi)Polygon.
- ’srid’int
SRID (spatial reference ID) of grid district geometry.
- Returns
Dictionary with MV grid district information. For more information on the dictionary see input parameter grid_district.
- Return type
- property rings¶
List of rings in the grid topology.
A ring is represented by the names of buses within that ring.
- property equipment_data¶
Technical data of electrical equipment such as lines and transformers.
- Returns
Dictionary with pandas.DataFrame containing equipment data. Keys of the dictionary are ‘mv_transformers’, ‘mv_overhead_lines’, ‘mv_cables’, ‘lv_transformers’, and ‘lv_cables’.
- Return type
- get_connected_lines_from_bus(bus_name)[source]¶
Returns all lines connected to specified bus.
- get_line_connecting_buses(bus_1, bus_2)[source]¶
Returns information of line connecting bus_1 and bus_2.
- Parameters
- Returns
Dataframe with information of line connecting bus_1 and bus_2 in the same format as
lines_df.- Return type
- get_connected_components_from_bus(bus_name)[source]¶
Returns dictionary of components connected to specified bus.
- Parameters
bus_name (str) – Identifier of bus to get connected components for.
- Returns
Dictionary of connected components with keys ‘generators’, ‘loads’, ‘storage_units’, ‘lines’, ‘transformers’, ‘transformers_hvmv’, ‘switches’. Corresponding values are component dataframes containing only components that are connected to the given bus.
- Return type
dict of pandas.DataFrame
- add_load(bus, p_set, type='conventional_load', **kwargs)[source]¶
Adds load to topology.
Load name is generated automatically.
- Parameters
type (str) – See
loads_dffor more information. Default: “conventional_load”kwargs – Kwargs may contain any further attributes you want to specify. See
loads_dffor more information on additional attributes used for some functionalities in edisgo. Kwargs may also contain a load ID (provided through keyword argument load_id as string) used to generate a unique identifier for the newly added load.
- Returns
Unique identifier of added load.
- Return type
- add_generator(bus, p_nom, generator_type, control='PQ', **kwargs)[source]¶
Adds generator to topology.
Generator name is generated automatically.
- Parameters
bus (str) – See
generators_dffor more information.p_nom (float) – See
generators_dffor more information.generator_type (str) – Type of generator, e.g. ‘solar’ or ‘gas’. See ‘type’ in
generators_dffor more information.control (str) – See
generators_dffor more information. Defaults to ‘PQ’.kwargs – Kwargs may contain any further attributes you want to specify. See
generators_dffor more information on additional attributes used for some functionalities in edisgo. Kwargs may also contain a generator ID (provided through keyword argument generator_id as string) used to generate a unique identifier for the newly added generator.
- Returns
Unique identifier of added generator.
- Return type
- add_storage_unit(bus, p_nom, control='PQ', **kwargs)[source]¶
Adds storage unit to topology.
Storage unit name is generated automatically.
- Parameters
bus (str) – See
storage_units_dffor more information.p_nom (float) – See
storage_units_dffor more information.control (str, optional) – See
storage_units_dffor more information. Defaults to ‘PQ’.kwargs – Kwargs may contain any further attributes you want to specify.
- add_line(bus0, bus1, length, **kwargs)[source]¶
Adds line to topology.
Line name is generated automatically. If type_info is provided, x, r, b and s_nom are calculated.
- add_bus(bus_name, v_nom, **kwargs)[source]¶
Adds bus to topology.
If provided bus name already exists, a unique name is created.
- Parameters
- Returns
Name of bus. If provided bus name already exists, a unique name is created.
- Return type
- remove_load(name)[source]¶
Removes load with given name from topology.
If no other elements are connected, line and bus are removed as well.
- remove_generator(name)[source]¶
Removes generator with given name from topology.
If no other elements are connected, line and bus are removed as well.
- Parameters
name (str) – Identifier of generator as specified in index of
generators_df.
- remove_storage_unit(name)[source]¶
Removes storage with given name from topology.
If no other elements are connected, line and bus are removed as well.
- Parameters
name (str) – Identifier of storage as specified in index of
storage_units_df.
- remove_line(name)[source]¶
Removes line with given name from topology.
Line is only removed, if it does not result in isolated buses. A warning is raised in that case.
- remove_bus(name)[source]¶
Removes bus with given name from topology.
Notes
Only isolated buses can be deleted from topology. Use respective functions first to delete all connected components (e.g. lines, transformers, loads, etc.). Use function
get_connected_components_from_bus()to get all connected components.
- update_number_of_parallel_lines(lines_num_parallel)[source]¶
Changes number of parallel lines and updates line attributes.
When number of parallel lines changes, attributes x, r, b, and s_nom have to be adapted, which is done in this function.
- Parameters
lines_num_parallel (pandas.Series) – Index contains identifiers of lines to update as in index of
lines_dfand values of series contain corresponding new number of parallel lines.
- change_line_type(lines, new_line_type)[source]¶
Changes line type of specified lines to given new line type.
Be aware that this function replaces the lines by one line of the given line type. Lines must all be in the same voltage level and the new line type must be a cable with technical parameters given in equipment parameters.
- connect_to_mv(edisgo_object, comp_data, comp_type='generator')[source]¶
Add and connect new generator, charging point or heat pump to MV grid topology.
This function creates a new bus the new component is connected to. The new bus is then connected to the grid depending on the specified voltage level (given in comp_data parameter). Components of voltage level 4 are connected to the HV/MV station. Components of voltage level 5 are connected to the nearest MV bus or line. In case the component is connected to a line, the line is split at the point closest to the new component (using perpendicular projection) and a new branch tee is added to connect the new component to.
- Parameters
edisgo_object (
EDisGo) –comp_data (dict) – Dictionary with all information on component. The dictionary must contain all required arguments of method
add_generatorrespectivelyadd_load, except the bus that is assigned in this function, and may contain all other parameters of those methods. Additionally, the dictionary must contain the voltage level to connect in key ‘voltage_level’ and the geolocation in key ‘geom’. The voltage level must be provided as integer, with possible options being 4 (component is connected directly to the HV/MV station) or 5 (component is connected somewhere in the MV grid). The geolocation must be provided as Shapely Point object.comp_type (str) – Type of added component. Can be ‘generator’, ‘charging_point’ or ‘heat_pump’. Default: ‘generator’.
- Returns
The identifier of the newly connected component.
- Return type
- connect_to_lv(edisgo_object, comp_data, comp_type='generator', allowed_number_of_comp_per_bus=2)[source]¶
Add and connect new generator, charging point or heat pump to LV grid topology.
This function connects the new component depending on the voltage level, and information on the MV/LV substation ID, geometry and sector, all provided in the comp_data parameter. It connects
- Components with specified voltage level 6
to MV/LV substation (a new bus is created for the new component, unless no geometry data is available, in which case the new component is connected directly to the substation)
- Generators with specified voltage level 7
with a nominal capacity of <=30 kW to LV loads of sector residential, if available
with a nominal capacity of >30 kW to LV loads of sector retail, industrial or agricultural, if available
to random bus in the LV grid as fallback if no appropriate load is available
- Charging points with specified voltage level 7
with sector ‘home’ to LV loads of sector residential, if available
with sector ‘work’ to LV loads of sector retail, industrial or agricultural, if available, otherwise
with sector ‘public’ or ‘hpc’ to some bus in the grid that is not a house connection
to random bus in the LV grid that is not a house connection if no appropriate load is available (fallback)
- Heat pumps with specified voltage level 7
with sector ‘individual_heating’ to LV loads
with sector ‘individual_heating’ to some bus in the grid that is not a house connection
to random bus in the LV grid that if no appropriate load is available (fallback)
In case no MV/LV substation ID is provided a random LV grid is chosen. In case the provided MV/LV substation ID does not exist (i.e. in case of components in an aggregated load area), the new component is directly connected to the HV/MV station (will be changed once generators in aggregated areas are treated differently in ding0).
The number of components of the same type connected at one load is restricted by the parameter allowed_number_of_comp_per_bus. If every possible load already has more than the allowed number then the new component is directly connected to the MV/LV substation.
- Parameters
edisgo_object (
EDisGo) –comp_data (dict) – Dictionary with all information on component. The dictionary must contain all required arguments of method
add_generatorrespectivelyadd_load, except the bus that is assigned in this function, and may contain all other parameters of those methods. Additionally, the dictionary must contain the voltage level to connect in key ‘voltage_level’ and may contain the geolocation in key ‘geom’ and the LV grid ID to connect the component in key ‘mvlv_subst_id’. The voltage level must be provided as integer, with possible options being 6 (component is connected directly to the MV/LV substation) or 7 (component is connected somewhere in the LV grid). The geolocation must be provided as Shapely Point object and the LV grid ID as integer.comp_type (str) – Type of added component. Can be ‘generator’, ‘charging_point’ or ‘heat_pump’. Default: ‘generator’.
allowed_number_of_comp_per_bus (int) – Specifies, how many components of the same type are at most allowed to be placed at the same bus. Default: 2.
- Returns
The identifier of the newly connected component.
- Return type
Notes
For the allocation, loads are selected randomly (sector-wise) using a predefined seed to ensure reproducibility.
- to_graph()[source]¶
Returns graph representation of the grid.
- Returns
Graph representation of the grid as networkx Ordered Graph, where lines are represented by edges in the graph, and buses and transformers are represented by nodes.
- Return type
- to_geopandas(mode='mv')[source]¶
Returns components as geopandas.GeoDataFrames.
Returns container with geopandas.GeoDataFrames containing all georeferenced components within the grid.
- Parameters
mode (str) – Return mode. If mode is “mv” the mv components are returned. If mode is “lv” a generator with a container per lv grid is returned. Default: “mv”
- Returns
Data container with GeoDataFrames containing all georeferenced components within the grid(s).
- Return type
- to_csv(directory)[source]¶
Exports topology to csv files.
The following attributes are exported:
‘loads_df’ : Attribute
loads_dfis saved to loads.csv.‘generators_df’ : Attribute
generators_dfis saved to generators.csv.‘storage_units_df’ : Attribute
storage_units_dfis saved to storage_units.csv.‘transformers_df’ : Attribute
transformers_dfis saved to transformers.csv.‘transformers_hvmv_df’ : Attribute
transformers_dfis saved to transformers.csv.‘lines_df’ : Attribute
lines_dfis saved to lines.csv.‘buses_df’ : Attribute
buses_dfis saved to buses.csv.‘switches_df’ : Attribute
switches_dfis saved to switches.csv.‘grid_district’ : Attribute
grid_districtis saved to network.csv.
Attributes are exported in a way that they can be directly imported to pypsa.
- Parameters
directory (str) – Path to save topology to.