edisgo.grid package¶
Submodules¶
edisgo.grid.components module¶
-
class
edisgo.grid.components.Component(**kwargs)[source]¶ Bases:
objectGeneric component
Notes
In case of a MV-LV voltage station,
gridrefers to the LV grid.-
geom¶ Location of component
Returns: Location of the Componentas Shapely Point or LineStringReturn type: Shapely Point object or Shapely LineString object
-
-
class
edisgo.grid.components.Station(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentStation object (medium or low voltage)
Represents a station, contains transformers.
-
transformers¶ Transformers located in station
Type: listofTransformer
-
-
class
edisgo.grid.components.Transformer(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentTransformer object
-
_type¶ Specification of type, refers to ToDo: ADD CORRECT REF TO (STATIC) DATA
Type: pandas.DataFrame
-
mv_grid¶
-
voltage_op¶
-
type¶
-
-
class
edisgo.grid.components.Load(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentLoad object
-
_timeseries¶ See timeseries getter for more information.
Type: pandas.Series, optional
-
_timeseries_reactive¶ See timeseries_reactive getter for more information.
Type: pandas.Series, optional
-
timeseries¶ Load time series
It returns the actual time series used in power flow analysis. If
_timeseriesis notNone, it is returned. Otherwise,timeseries()looks for time series of the according sector inTimeSeriesobject.Returns: DataFrame containing active power in kW in column ‘p’ and reactive power in kVA in column ‘q’. Return type: pandas.DataFrame
-
timeseries_reactive¶ Reactive power time series in kvar.
Parameters: timeseries_reactive (pandas.Seriese) – Series containing reactive power in kvar. Returns: Series containing reactive power time series in kvar. If it is not set it is tried to be retrieved from load_reactive_power attribute of global TimeSeries object. If that is not possible None is returned. Return type: pandas.Series or None
-
pypsa_timeseries(attr)[source]¶ Return time series in PyPSA format
Parameters: attr (str) – Attribute name (PyPSA conventions). Choose from {p_set, q_set}
-
consumption¶ Annual consumption per sector in kWh
Sectors
- retail/industrial
- agricultural
- residential
The format of the
dictis as follows:{ 'residential': 453.4 }
Type: dict
-
peak_load¶ Get sectoral peak load
-
power_factor¶ Power factor of load
Parameters: power_factor ( float) – Ratio of real power to apparent power.Returns: Ratio of real power to apparent power. If power factor is not set it is retrieved from the network config object depending on the grid level the load is in. Return type: float
-
reactive_power_mode¶ Power factor mode of Load.
This information is necessary to make the load behave in an inductive or capacitive manner. Essentially this changes the sign of the reactive power.
The convention used here in a load is that: - when reactive_power_mode is ‘inductive’ then Q is positive - when reactive_power_mode is ‘capacitive’ then Q is negative
Parameters: reactive_power_mode ( stror None) – Possible options are ‘inductive’, ‘capacitive’ and ‘not_applicable’. In the case of ‘not_applicable’ a reactive power time series must be given.Returns: In the case that this attribute is not set, it is retrieved from the network config object depending on the voltage level the load is in. Return type: str
-
q_sign¶ Get the sign of reactive power based on
_reactive_power_mode.Returns: In case of inductive reactive power returns +1 and in case of capacitive reactive power returns -1. If reactive power time series is given, q_sign is set to None. Return type: intor None
-
-
class
edisgo.grid.components.Generator(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentGenerator object
-
_timeseries¶ See timeseries getter for more information.
Type: pandas.Series, optional
-
_type¶ See type getter for more information.
Type: pandas.Series, optional
-
_q_sign See q_sign getter for more information.
Type: int, optional
Notes
The attributes
_typeand_subtypehave to match the corresponding types inTimeseriesto allow allocation of time series to generators.See also
edisgo.network.TimeSeries- Details of global
TimeSeries
-
timeseries¶ Feed-in time series of generator
It returns the actual dispatch time series used in power flow analysis. If
_timeseriesis notNone, it is returned. Otherwise,timeseries()looks for time series of the according type of technology inTimeSeries. If the reactive power time series is provided through_timeseries_reactive, this is added to_timeseries. When_timeseries_reactiveis not set, the reactive power is also calculated in_timeseriesusingpower_factorandreactive_power_mode. Thepower_factordetermines the magnitude of the reactive power based on the power factor and active power provided and thereactive_power_modedetermines if the reactive power is either consumed (inductive behaviour) or provided (capacitive behaviour).Returns: DataFrame containing active power in kW in column ‘p’ and reactive power in kvar in column ‘q’. Return type: pandas.DataFrame
-
timeseries_reactive¶ Reactive power time series in kvar.
Parameters: timeseries_reactive (pandas.Seriese) – Series containing reactive power in kvar. Returns: Series containing reactive power time series in kvar. If it is not set it is tried to be retrieved from generation_reactive_power attribute of global TimeSeries object. If that is not possible None is returned. Return type: pandas.Series or None
-
pypsa_timeseries(attr)[source]¶ Return time series in PyPSA format
Convert from kW, kVA to MW, MVA
Parameters: attr ( str) – Attribute name (PyPSA conventions). Choose from {p_set, q_set}
-
power_factor¶ Power factor of generator
Parameters: power_factor ( float) – Ratio of real power to apparent power.Returns: Ratio of real power to apparent power. If power factor is not set it is retrieved from the network config object depending on the grid level the generator is in. Return type: float
-
reactive_power_mode¶ Power factor mode of generator.
This information is necessary to make the generator behave in an inductive or capacitive manner. Essentially this changes the sign of the reactive power.
The convention used here in a generator is that: - when reactive_power_mode is ‘capacitive’ then Q is positive - when reactive_power_mode is ‘inductive’ then Q is negative
In the case that this attribute is not set, it is retrieved from the network config object depending on the voltage level the generator is in.
Parameters: reactive_power_mode ( stror None) – Possible options are ‘inductive’, ‘capacitive’ and ‘not_applicable’. In the case of ‘not_applicable’ a reactive power time series must be given.Returns: :obj:`str` – In the case that this attribute is not set, it is retrieved from the network config object depending on the voltage level the generator is in. Return type: Power factor mode
-
q_sign¶ Get the sign of reactive power based on
_reactive_power_mode.Returns: In case of inductive reactive power returns -1 and in case of capacitive reactive power returns +1. If reactive power time series is given, q_sign is set to None. Return type: intor None
-
-
class
edisgo.grid.components.GeneratorFluctuating(**kwargs)[source]¶ Bases:
edisgo.grid.components.GeneratorGenerator object for fluctuating renewables.
-
_curtailment¶ See curtailment getter for more information.
Type: pandas.Series
-
timeseries¶ Feed-in time series of generator
It returns the actual time series used in power flow analysis. If
_timeseriesis notNone, it is returned. Otherwise,timeseries()looks for generation and curtailment time series of the according type of technology (and weather cell) inTimeSeries.Returns: DataFrame containing active power in kW in column ‘p’ and reactive power in kVA in column ‘q’. Return type: pandas.DataFrame
-
timeseries_reactive¶ Reactive power time series in kvar.
:param pandas.Series: Series containing reactive power time series in kvar.
Returns: Series containing reactive power time series in kvar. If it is not set it is tried to be retrieved from generation_reactive_power attribute of global TimeSeries object. If that is not possible None is returned. Return type: pandas.DataFrame or None
-
curtailment¶ param curtailment_ts: See class definition for details. :type curtailment_ts: pandas.Series
Returns: If self._curtailment is set it returns that. Otherwise, if curtailment in TimeSeriesfor the corresponding technology type (and if given, weather cell ID) is set this is returned.Return type: pandas.Series
-
-
class
edisgo.grid.components.Storage(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentStorage object
Describes a single storage instance in the eDisGo grid. Includes technical parameters such as
Storage.efficiency_inorStorage.standing_lossas well as its time series of operationStorage.timeseries().-
timeseries¶ Time series of storage operation
Parameters: ts (pandas.DataFrame) – DataFrame containing active power the storage is charged (negative) and discharged (positive) with (on the grid side) in kW in column ‘p’ and reactive power in kvar in column ‘q’. When ‘q’ is positive, reactive power is supplied (behaving as a capacitor) and when ‘q’ is negative reactive power is consumed (behaving as an inductor). Returns: See parameter timeseries. Return type: pandas.DataFrame
-
pypsa_timeseries(attr)[source]¶ Return time series in PyPSA format
Convert from kW, kVA to MW, MVA
Parameters: attr (str) – Attribute name (PyPSA conventions). Choose from {p_set, q_set}
-
nominal_power¶ Nominal charging and discharging power of storage instance in kW.
Returns: Storage nominal power Return type: float
-
max_hours¶ Maximum state of charge capacity in terms of hours at full discharging power nominal_power.
Returns: Hours storage can be discharged for at nominal power Return type: float
-
nominal_capacity¶ Nominal storage capacity in kWh.
Returns: Storage nominal capacity Return type: float
-
efficiency_in¶ Storage charging efficiency in per unit.
Returns: Charging efficiency in range of 0..1 Return type: float
-
efficiency_out¶ Storage discharging efficiency in per unit.
Returns: Discharging efficiency in range of 0..1 Return type: float
-
standing_loss¶ Standing losses of storage in %/100 / h
Losses relative to SoC per hour. The unit is pu (%/100%). Hence, it ranges from 0..1.
Returns: Standing losses in pu. Return type: float
-
power_factor¶ Power factor of storage
If power factor is not set it is retrieved from the network config object depending on the grid level the storage is in.
Returns: :obj:`float` – Ratio of real power to apparent power. Return type: Power factor
-
reactive_power_mode¶ Power factor mode of storage.
If the power factor is set, then it is necessary to know whether it is leading or lagging. In other words this information is necessary to make the storage behave in an inductive or capacitive manner. Essentially this changes the sign of the reactive power Q.
The convention used here in a storage is that: - when reactive_power_mode is ‘capacitive’ then Q is positive - when reactive_power_mode is ‘inductive’ then Q is negative
In the case that this attribute is not set, it is retrieved from the network config object depending on the voltage level the storage is in.
Returns: Either ‘inductive’ or ‘capacitive’ Return type: obj: str : Power factor mode
-
q_sign¶ Get the sign reactive power based on the :attr: _reactive_power_mode
Returns: Return type: obj: int : +1 or -1
-
-
class
edisgo.grid.components.MVDisconnectingPoint(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentDisconnecting point object
Medium voltage disconnecting points = points where MV rings are split under normal operation conditions (= switch disconnectors in DINGO).
-
state¶ Get state of switch disconnector
Returns: State of MV ring disconnector: ‘open’ or ‘closed’. Returns None if switch disconnector line segment is not set. This refers to an open ring, but it’s unknown if the grid topology was built correctly.
Return type: str or None
-
line¶ Get or set line segment that belongs to the switch disconnector
The setter allows only to set the respective line initially. Once the line segment representing the switch disconnector is set, it cannot be changed.
Returns: Line segment that is part of the switch disconnector model Return type: Line
-
-
class
edisgo.grid.components.BranchTee(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentBranch tee object
A branch tee is used to branch off a line to connect another node (german: Abzweigmuffe)
-
class
edisgo.grid.components.MVStation(**kwargs)[source]¶ Bases:
edisgo.grid.components.StationMV Station object
-
class
edisgo.grid.components.LVStation(**kwargs)[source]¶ Bases:
edisgo.grid.components.StationLV Station object
-
mv_grid¶
-
-
class
edisgo.grid.components.Line(**kwargs)[source]¶ Bases:
edisgo.grid.components.ComponentLine object
Parameters: - _type (pandas.Series) –
Equipment specification including R and X for power flow analysis Columns:
Column Description Unit Data type name Name (e.g. NAYY..) str U_n Nominal voltage kV int I_max_th Max. th. current A float R Resistance Ohm/km float L Inductance mH/km float C Capacitance uF/km float Source Data source - str - _length (float) – Length of the line calculated in linear distance. Unit: m
- _quantity (float) – Quantity of parallel installed lines.
- _kind (String) – Specifies whether the line is an underground cable (‘cable’) or an overhead line (‘line’).
-
geom¶ Provide Shapely LineString object geometry of
Line
-
type¶
-
length¶
-
quantity¶
-
kind¶
- _type (pandas.Series) –
edisgo.grid.connect module¶
-
edisgo.grid.connect.connect_mv_generators(network)[source]¶ Connect MV generators to existing grids.
This function searches for unconnected generators in MV grids and connects them.
It connects
- generators of voltage level 4
- to HV-MV station
- generators of voltage level 5
- with a nom. capacity of <=30 kW to LV loads of type residential
- with a nom. capacity of >30 kW and <=100 kW to LV loads of type
- retail, industrial or agricultural
- to the MV-LV station if no appropriate load is available (fallback)
Parameters: network ( Network) – The eDisGo container objectNotes
Adapted from Ding0.
-
edisgo.grid.connect.connect_lv_generators(network, allow_multiple_genos_per_load=True)[source]¶ Connect LV generators to existing grids.
This function searches for unconnected generators in all LV grids and connects them.
It connects
- generators of voltage level 6
- to MV-LV station
- generators of voltage level 7
- with a nom. capacity of <=30 kW to LV loads of type residential
- with a nom. capacity of >30 kW and <=100 kW to LV loads of type
- retail, industrial or agricultural
- to the MV-LV station if no appropriate load is available (fallback)
Parameters: Notes
For the allocation, loads are selected randomly (sector-wise) using a predefined seed to ensure reproducibility.
edisgo.grid.grids module¶
-
class
edisgo.grid.grids.Grid(**kwargs)[source]¶ Bases:
objectDefines a basic grid in eDisGo
-
_grid_district¶ Contains information about grid district (supplied region) of grid, format: ToDo: DEFINE FORMAT
Type: dict
-
_generators¶ Contains a list of the generators
Type: :obj:’edisgo.components.Generator’
-
_loads¶ Contains a list of the loads
Type: :obj:’edisgo.components.Load’
-
connect_generators(generators)[source]¶ Connects generators to grid
Parameters: generators (pandas.DataFrame) – Generators to be connected
-
graph¶ Provide access to the graph
-
station¶ Provide access to station
-
voltage_nom¶ Provide access to nominal voltage
-
id¶
-
network¶
-
grid_district¶ Provide access to the grid_district
-
weather_cells¶ Weather cells contained in grid
Returns: list of weather cell ids contained in grid Return type: list
-
peak_generation¶ Cumulative peak generation capacity of generators of this grid
Returns: Ad-hoc calculated or cached peak generation capacity Return type: float
-
peak_generation_per_technology¶ Peak generation of each technology in the grid
Returns: Peak generation index by technology Return type: pandas.Series
-
peak_generation_per_technology_and_weather_cell¶ Peak generation of each technology and the corresponding weather cell in the grid
Returns: Peak generation index by technology Return type: pandas.Series
-
peak_load¶ Cumulative peak load capacity of generators of this grid
Returns: Ad-hoc calculated or cached peak load capacity Return type: float
-
consumption¶ Consumption in kWh per sector for whole grid
Returns: Indexed by demand sector Return type: pandas.Series
-
-
class
edisgo.grid.grids.MVGrid(**kwargs)[source]¶ Bases:
edisgo.grid.grids.GridDefines a medium voltage grid in eDisGo
-
_mv_disconn_points¶ -
Medium voltage disconnecting points = points where MV rings are split under normal operation conditions (= switch disconnectors in DINGO).
Type: listof
-
-
class
edisgo.grid.grids.LVGrid(**kwargs)[source]¶ Bases:
edisgo.grid.grids.GridDefines a low voltage grid in eDisGo
-
class
edisgo.grid.grids.Graph(incoming_graph_data=None, **attr)[source]¶ Bases:
networkx.classes.graph.GraphGraph object
This graph is an object subclassed from networkX.Graph extended by extra functionality and specific methods.
-
nodes_from_line(line)[source]¶ Get nodes adjacent to line
Here, line refers to the object behind the key ‘line’ of the attribute dict attached to each edge.
Parameters: line (edisgo.grid.components.Line) – A eDisGo line object Returns: Nodes adjacent to this edge Return type: tuple
-
line_from_nodes(u, v)[source]¶ Get line between two nodes
uandv.Parameters: Returns: Line segment connecting
uandv.Return type:
-
nodes_by_attribute(attr_val, attr='type')[source]¶ Select Graph’s nodes by attribute value
Get all nodes that share the same attribute. By default, the attr ‘type’ is used to specify the nodes type (generator, load, etc.).
Examples
>>> import edisgo >>> G = edisgo.grids.Graph() >>> G.add_node(1, type='generator') >>> G.add_node(2, type='load') >>> G.add_node(3, type='generator') >>> G.nodes_by_attribute('generator') [1, 3]
Parameters: Returns: A list containing nodes elements that match the given attribute value
Return type:
-
lines_by_attribute(attr_val=None, attr='type')[source]¶ Returns a generator for iterating over Graph’s lines by attribute value.
Get all lines that share the same attribute. By default, the attr ‘type’ is used to specify the lines’ type (line, agg_line, etc.).
The edge of a graph is described by the two adjacent nodes and the line object itself. Whereas the line object is used to hold all relevant power system parameters.
Examples
>>> import edisgo >>> G = edisgo.grids.Graph() >>> G.add_node(1, type='generator') >>> G.add_node(2, type='load') >>> G.add_edge(1, 2, type='line') >>> lines = G.lines_by_attribute('line') >>> list(lines)[0] <class 'tuple'>: ((node1, node2), line)
Parameters: Returns: A list containing line elements that match the given attribute value
Return type: Generator of
dictNotes
There are generator functions for nodes (Graph.nodes()) and edges (Graph.edges()) in NetworkX but unlike graph nodes, which can be represented by objects, branch objects can only be accessed by using an edge attribute (‘line’ is used here)
To make access to attributes of the line objects simpler and more intuitive for the user, this generator yields a dictionary for each edge that contains information about adjacent nodes and the line object.
Note, the construction of the dictionary highly depends on the structure of the in-going tuple (which is defined by the needs of networkX). If this changes, the code will break.
Adapted from Dingo.
-
edisgo.grid.network module¶
-
class
edisgo.grid.network.EDisGoReimport(results_path, **kwargs)[source]¶ Bases:
objectEDisGo class created from saved results.
-
plot_mv_grid_topology(technologies=False, **kwargs)[source]¶ Plots plain MV grid topology and optionally nodes by technology type (e.g. station or generator).
Parameters: technologies ( Boolean) – If True plots stations, generators, etc. in the grid in different colors. If False does not plot any nodes. Default: False.:param For more information see
edisgo.tools.plots.mv_grid_topology().:
-
plot_mv_voltages(**kwargs)[source]¶ Plots voltages in MV grid on grid topology plot.
For more information see
edisgo.tools.plots.mv_grid_topology().
-
plot_mv_line_loading(**kwargs)[source]¶ Plots relative line loading (current from power flow analysis to allowed current) of MV lines.
For more information see
edisgo.tools.plots.mv_grid_topology().
-
plot_mv_grid_expansion_costs(**kwargs)[source]¶ Plots costs per MV line.
For more information see
edisgo.tools.plots.mv_grid_topology().
-
plot_mv_storage_integration(**kwargs)[source]¶ Plots storage position in MV grid of integrated storages.
For more information see
edisgo.tools.plots.mv_grid_topology().
-
histogram_voltage(timestep=None, title=True, **kwargs)[source]¶ Plots histogram of voltages.
For more information on the histogram plot and possible configurations see
edisgo.tools.plots.histogram().Parameters: - timestep (pandas.Timestamp or list(pandas.Timestamp) or None, optional) – Specifies time steps histogram is plotted for. If timestep is None all time steps voltages are calculated for are used. Default: None.
- title (
strorbool, optional) – Title for plot. If True title is auto generated. If False plot has no title. Ifstr, the provided title is used. Default: True.
-
histogram_relative_line_load(timestep=None, title=True, voltage_level='mv_lv', **kwargs)[source]¶ Plots histogram of relative line loads.
For more information on how the relative line load is calculated see
edisgo.tools.tools.get_line_loading_from_network(). For more information on the histogram plot and possible configurations seeedisgo.tools.plots.histogram().Parameters: - timestep (pandas.Timestamp or list(pandas.Timestamp) or None, optional) – Specifies time step(s) histogram is plotted for. If timestep is None all time steps currents are calculated for are used. Default: None.
- title (
strorbool, optional) – Title for plot. If True title is auto generated. If False plot has no title. Ifstr, the provided title is used. Default: True. - voltage_level (
str) – Specifies which voltage level to plot voltage histogram for. Possible options are ‘mv’, ‘lv’ and ‘mv_lv’. ‘mv_lv’ is also the fallback option in case of wrong input. Default: ‘mv_lv’
-
-
class
edisgo.grid.network.EDisGo(**kwargs)[source]¶ Bases:
edisgo.grid.network.EDisGoReimportProvides the top-level API for invocation of data import, analysis of hosting capacity, grid reinforcement and flexibility measures.
Parameters: - worst_case_analysis (None or
str, optional) –If not None time series for feed-in and load will be generated according to the chosen worst case analysis Possible options are:
- ’worst-case’ feed-in for the two worst-case scenarios feed-in case and load case are generated
- ’worst-case-feedin’ feed-in for the worst-case scenario feed-in case is generated
- ’worst-case-load’ feed-in for the worst-case scenario load case is generated
Be aware that if you choose to conduct a worst-case analysis your input for the following parameters will not be used: * timeseries_generation_fluctuating * timeseries_generation_dispatchable * timeseries_load
- mv_grid_id (
str) –MV grid ID used in import of ding0 grid.
- ding0_grid (file:
strording0.core.NetworkDing0) – If a str is provided it is assumed it points to a pickle with Ding0 grid data. This file will be read. If an object of the typeding0.core.NetworkDing0data will be used directly from this object. This will probably be removed when ding0 grids are in oedb. - config_path (None or
strordict) –Path to the config directory. Options are:
- None If config_path is None configs are loaded from the edisgo default config directory ($HOME$/.edisgo). If the directory does not exist it is created. If config files don’t exist the default config files are copied into the directory.
strIf config_path is a string configs will be loaded from the directory specified by config_path. If the directory does not exist it is created. If config files don’t exist the default config files are copied into the directory.dictA dictionary can be used to specify different paths to the different config files. The dictionary must have the following keys:- ’config_db_tables’
- ’config_grid’
- ’config_grid_expansion’
- ’config_timeseries’
Values of the dictionary are paths to the corresponding config file. In contrast to the other two options the directories and config files must exist and are not automatically created.
Default: None.
- scenario_description (None or
str) – Can be used to describe your scenario but is not used for anything else. Default: None. - timeseries_generation_fluctuating (
stror pandas.DataFrame) –Parameter used to obtain time series for active power feed-in of fluctuating renewables wind and solar. Possible options are:
- ’oedb’ Time series for the year 2011 are obtained from the OpenEnergy DataBase.
- pandas.DataFrame DataFrame with time series, normalized with corresponding capacity. Time series can either be aggregated by technology type or by type and weather cell ID. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell id. Index needs to be a pandas.DatetimeIndex.
- timeseries_generation_dispatchable (pandas.DataFrame) –
DataFrame with time series for active power of each (aggregated) type of dispatchable generator normalized with corresponding capacity. Index needs to be a pandas.DatetimeIndex. Columns represent generator type:
- ’gas’
- ’coal’
- ’biomass’
- ’other’
- …
Use ‘other’ if you don’t want to explicitly provide every possible type.
- timeseries_generation_reactive_power (pandas.DataFrame, optional) – DataFrame with time series of normalized reactive power (normalized by
the rated nominal active power) per technology and weather cell. Index
needs to be a pandas.DatetimeIndex.
Columns represent generator type and can be a MultiIndex column
containing the weather cell ID in the second level. If the technology
doesn’t contain weather cell information i.e. if it is other than solar
and wind generation, this second level can be left as a numpy Nan or a
None.
Default: None.
If no time series for the technology or technology and weather cell ID
is given, reactive power will be calculated from power factor and
power factor mode in the config sections reactive_power_factor and
reactive_power_mode and a warning will be raised. See
GeneratorandGeneratorFluctuatingfor more information. - timeseries_load (
stror pandas.DataFrame) –Parameter used to obtain time series of active power of (cumulative) loads. Possible options are:
- ’demandlib’ Time series for the year specified in timeindex are generated using the oemof demandlib.
- pandas.DataFrame DataFrame with load time series of each (cumulative) type of load normalized with corresponding annual energy demand. Index needs to be a pandas.DatetimeIndex. Columns represent load type: * ‘residential’ * ‘retail’ * ‘industrial’ * ‘agricultural’
- timeseries_load_reactive_power (pandas.DataFrame, optional) –
DataFrame with time series of normalized reactive power (normalized by annual energy demand) per load sector. Index needs to be a pandas.DatetimeIndex. Columns represent load type:
- ’residential’
- ’retail’
- ’industrial’
- ’agricultural’
Default: None. If no time series for the load sector is given, reactive power will be calculated from power factor and power factor mode in the config sections reactive_power_factor and reactive_power_mode and a warning will be raised. See
Loadfor more information. - generator_scenario (None or
str) –If provided defines which scenario of future generator park to use and invokes import of these generators. Possible options are ‘nep2035’ and ‘ego100’.
- timeindex (None or pandas.DatetimeIndex) – Can be used to select time ranges of the feed-in and load time series that will be used in the power flow analysis. Also defines the year load time series are obtained for when choosing the ‘demandlib’ option to generate load time series.
Examples
Assuming you have the Ding0 ding0_data.pkl in CWD
Create eDisGo Network object by loading Ding0 file
>>> from edisgo.grid.network import EDisGo >>> edisgo = EDisGo(ding0_grid='ding0_data.pkl', mode='worst-case-feedin')
Analyze hosting capacity for MV and LV grid level
>>> edisgo.analyze()
Print LV station secondary side voltage levels returned by PFA
>>> lv_stations = edisgo.network.mv_grid.graph.nodes_by_attribute( >>> 'lv_station') >>> print(edisgo.network.results.v_res(lv_stations, 'lv'))
-
curtail(methodology, curtailment_timeseries, **kwargs)[source]¶ Sets up curtailment time series.
Curtailment time series are written into
TimeSeries. SeeCurtailmentControlfor more information on parameters and methodologies.
-
import_from_ding0(file, **kwargs)[source]¶ Import grid data from DINGO file
For details see
edisgo.data.import_data.import_from_ding0()
-
import_generators(generator_scenario=None)[source]¶ Import generators
For details see
edisgo.data.import_data.import_generators()
-
analyze(mode=None, timesteps=None)[source]¶ Analyzes the grid by power flow analysis
Analyze the grid for violations of hosting capacity. Means, perform a power flow analysis and obtain voltages at nodes (load, generator, stations/transformers and branch tees) and active/reactive power at lines.
The power flow analysis can currently only be performed for both grid levels MV and LV. See ToDos section for more information.
A static non-linear power flow analysis is performed using PyPSA. The high-voltage to medium-voltage transformer are not included in the analysis. The slack bus is defined at secondary side of these transformers assuming an ideal tap changer. Hence, potential overloading of the transformers is not studied here.
Parameters: - mode (str) – Allows to toggle between power flow analysis (PFA) on the whole grid topology (MV + LV), only MV or only LV. Defaults to None which equals power flow analysis for MV + LV which is the only implemented option at the moment. See ToDos section for more information.
- timesteps (pandas.DatetimeIndex or pandas.Timestamp) – Timesteps specifies for which time steps to conduct the power flow
analysis. It defaults to None in which case the time steps in
timeseries.timeindex (see
TimeSeries) are used.
Notes
The current implementation always translates the grid topology representation to the PyPSA format and stores it to
self.network.pypsa.The option to export only the edisgo MV grid (mode = ‘mv’) to conduct a power flow analysis is implemented in
to_pypsa()but NotImplementedError is raised since the rest of edisgo does not handle this option yet. The analyze function will throw an error sinceprocess_pfa_results()does not handle aggregated loads and generators in the LV grids. Also, grid reinforcement, pypsa update of time series, and probably other functionalities do not work when only the MV grid is analysed.Further ToDos are: * explain how power plants are modeled, if possible use a link * explain where to find and adjust power flow analysis defining parameters
See also
to_pypsa()- Translator to PyPSA data format
-
analyze_lopf(mode=None, timesteps=None, etrago_max_storage_size=None)[source]¶ Analyzes the grid by power flow analysis
Analyze the grid for violations of hosting capacity. Means, perform a power flow analysis and obtain voltages at nodes (load, generator, stations/transformers and branch tees) and active/reactive power at lines.
The power flow analysis can currently only be performed for both grid levels MV and LV. See ToDos section for more information.
A static non-linear power flow analysis is performed using PyPSA. The high-voltage to medium-voltage transformer are not included in the analysis. The slack bus is defined at secondary side of these transformers assuming an ideal tap changer. Hence, potential overloading of the transformers is not studied here.
Parameters: - mode (str) – Allows to toggle between power flow analysis (PFA) on the whole grid topology (MV + LV), only MV or only LV. Defaults to None which equals power flow analysis for MV + LV which is the only implemented option at the moment. See ToDos section for more information.
- timesteps (pandas.DatetimeIndex or pandas.Timestamp) – Timesteps specifies for which time steps to conduct the power flow
analysis. It defaults to None in which case the time steps in
timeseries.timeindex (see
TimeSeries) are used.
Notes
The current implementation always translates the grid topology representation to the PyPSA format and stores it to
self.network.pypsa.The option to export only the edisgo MV grid (mode = ‘mv’) to conduct a power flow analysis is implemented in
to_pypsa()but NotImplementedError is raised since the rest of edisgo does not handle this option yet. The analyze function will throw an error sinceprocess_pfa_results()does not handle aggregated loads and generators in the LV grids. Also, grid reinforcement, pypsa update of time series, and probably other functionalities do not work when only the MV grid is analysed.Further ToDos are: * explain how power plants are modeled, if possible use a link * explain where to find and adjust power flow analysis defining parameters
See also
to_pypsa()- Translator to PyPSA data format
-
reinforce(**kwargs)[source]¶ Reinforces the grid and calculates grid expansion costs.
See
edisgo.flex_opt.reinforce_grid()for more information.
-
integrate_storage(timeseries, position, **kwargs)[source]¶ Integrates storage into grid.
See
StorageControlfor more information.
- worst_case_analysis (None or
-
class
edisgo.grid.network.Network(**kwargs)[source]¶ Bases:
objectUsed as container for all data related to a single
MVGrid.Parameters: - scenario_description (
str, optional) – Can be used to describe your scenario but is not used for anything else. Default: None. - config_path (None or
strordict, optional) – SeeConfigfor further information. Default: None. - metadata (
dict) – Metadata of Network such as ? - data_sources (
dictofstr) – Data Sources of grid, generators etc. Keys: ‘grid’, ‘generators’, ? - mv_grid (
MVGrid) – Medium voltage (MV) grid - generator_scenario (
str) – Defines which scenario of future generator park to use.
-
config¶ eDisGo configuration data.
Returns: Config object with configuration data from config files. Return type: Config
-
generator_scenario¶ Defines which scenario of future generator park to use.
Parameters: generator_scenario_name ( str) – Name of scenario of future generator parkReturns: Name of scenario of future generator park Return type: str
-
scenario_description¶ Used to describe your scenario but not used for anything else.
Parameters: scenario_description ( str) – Description of scenarioReturns: Scenario name Return type: str
-
equipment_data¶ Technical data of electrical equipment such as lines and transformers
Returns: Data of electrical equipment Return type: dictof pandas.DataFrame
-
mv_grid¶ Medium voltage (MV) grid
Parameters: mv_grid ( MVGrid) – Medium voltage (MV) gridReturns: Medium voltage (MV) grid Return type: MVGrid
-
timeseries¶ Object containing load and feed-in time series.
Parameters: timeseries ( TimeSeries) – Object containing load and feed-in time series.Returns: Object containing load and feed-in time series. Return type: TimeSeries
-
data_sources¶ Dictionary with data sources of grid, generators etc.
Returns: Data Sources of grid, generators etc. Return type: dictofstr
-
dingo_import_data¶ Temporary data from ding0 import needed for OEP generator update
-
pypsa¶ PyPSA grid representation
A grid topology representation based on pandas.DataFrame. The overall container object of this data model, the pypsa.Network, is assigned to this attribute.
Parameters: pypsa (pypsa.Network) – The PyPSA network container. Returns: PyPSA grid representation. The attribute edisgo_mode is added to specify if pypsa representation of the edisgo network was created for the whole grid topology (MV + LV), only MV or only LV. See parameter mode in analyze()for more information.Return type: pypsa.Network
- scenario_description (
-
class
edisgo.grid.network.Config(**kwargs)[source]¶ Bases:
objectContainer for all configurations.
Parameters: config_path (None or strordict) –Path to the config directory. Options are:
- None If config_path is None configs are loaded from the edisgo default config directory ($HOME$/.edisgo). If the directory does not exist it is created. If config files don’t exist the default config files are copied into the directory.
strIf config_path is a string configs will be loaded from the directory specified by config_path. If the directory does not exist it is created. If config files don’t exist the default config files are copied into the directory.dictA dictionary can be used to specify different paths to the different config files. The dictionary must have the following keys: * ‘config_db_tables’ * ‘config_grid’ * ‘config_grid_expansion’ * ‘config_timeseries’Values of the dictionary are paths to the corresponding config file. In contrast to the other two options the directories and config files must exist and are not automatically created.
Default: None.
Notes
The Config object can be used like a dictionary. See example on how to use it.
Examples
Create Config object from default config files
>>> from edisgo.grid.network import Config >>> config = Config()
Get reactive power factor for generators in the MV grid
>>> config['reactive_power_factor']['mv_gen']
-
class
edisgo.grid.network.TimeSeriesControl(network, **kwargs)[source]¶ Bases:
objectSets up TimeSeries Object.
Parameters: - network (
Network) – The eDisGo data container - mode (
str, optional) – Mode must be set in case of worst-case analyses and can either be ‘worst-case’ (both feed-in and load case), ‘worst-case-feedin’ (only feed-in case) or ‘worst-case-load’ (only load case). All other parameters except of config-data will be ignored. Default: None. - timeseries_generation_fluctuating (
stror pandas.DataFrame, optional) –Parameter used to obtain time series for active power feed-in of fluctuating renewables wind and solar. Possible options are:
- ’oedb’ Time series for 2011 are obtained from the OpenEnergy DataBase. mv_grid_id and scenario_description have to be provided when choosing this option.
- pandas.DataFrame DataFrame with time series, normalized with corresponding capacity. Time series can either be aggregated by technology type or by type and weather cell ID. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID.
Default: None.
- timeseries_generation_dispatchable (pandas.DataFrame, optional) –
DataFrame with time series for active power of each (aggregated) type of dispatchable generator normalized with corresponding capacity. Columns represent generator type:
- ’gas’
- ’coal’
- ’biomass’
- ’other’
- …
Use ‘other’ if you don’t want to explicitly provide every possible type. Default: None.
- timeseries_generation_reactive_power (pandas.DataFrame, optional) –
DataFrame with time series of normalized reactive power (normalized by the rated nominal active power) per technology and weather cell. Index needs to be a pandas.DatetimeIndex. Columns represent generator type and can be a MultiIndex column containing the weather cell ID in the second level. If the technology doesn’t contain weather cell information i.e. if it is other than solar and wind generation, this second level can be left as an empty string ‘’.
Default: None.
- timeseries_load (
stror pandas.DataFrame, optional) –Parameter used to obtain time series of active power of (cumulative) loads. Possible options are:
- ’demandlib’ Time series are generated using the oemof demandlib.
- pandas.DataFrame
DataFrame with load time series of each (cumulative) type of load
normalized with corresponding annual energy demand.
Columns represent load type:
- ’residential’
- ’retail’
- ’industrial’
- ’agricultural’
Default: None.
- timeseries_load_reactive_power (pandas.DataFrame, optional) –
Parameter to get the time series of the reactive power of loads. It should be a DataFrame with time series of normalized reactive power (normalized by annual energy demand) per load sector. Index needs to be a pandas.DatetimeIndex. Columns represent load type:
- ’residential’
- ’retail’
- ’industrial’
- ’agricultural’
Default: None.
- timeindex (pandas.DatetimeIndex) – Can be used to define a time range for which to obtain load time series and feed-in time series of fluctuating renewables or to define time ranges of the given time series that will be used in the analysis.
- network (
-
class
edisgo.grid.network.CurtailmentControl(edisgo, methodology, curtailment_timeseries, **kwargs)[source]¶ Bases:
objectAllocates given curtailment targets to solar and wind generators.
Parameters: - edisgo (
edisgo.EDisGo) – The parent EDisGo object that this instance is a part of. - methodology (
str) –Defines the curtailment strategy. Possible options are:
- ’feedin-proportional’
The curtailment that has to be met in each time step is allocated
equally to all generators depending on their share of total
feed-in in that time step. For more information see
edisgo.flex_opt.curtailment.feedin_proportional(). - ’voltage-based’
The curtailment that has to be met in each time step is allocated
based on the voltages at the generator connection points and a
defined voltage threshold. Generators at higher voltages
are curtailed more. The default voltage threshold is 1.0 but
can be changed by providing the argument ‘voltage_threshold’. This
method formulates the allocation of curtailment as a linear
optimization problem using
Pyomoand requires a linear programming solver like coin-or cbc (cbc) or gnu linear programming kit (glpk). The solver can be specified through the parameter ‘solver’. For more information seeedisgo.flex_opt.curtailment.voltage_based().
- ’feedin-proportional’
The curtailment that has to be met in each time step is allocated
equally to all generators depending on their share of total
feed-in in that time step. For more information see
- curtailment_timeseries (pandas.Series or pandas.DataFrame, optional) – Series or DataFrame containing the curtailment time series in kW. Index needs to be a pandas.DatetimeIndex. Provide a Series if the curtailment time series applies to wind and solar generators. Provide a DataFrame if the curtailment time series applies to a specific technology and optionally weather cell. In the first case columns of the DataFrame are e.g. ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID. Default: None.
- solver (
str) –The solver used to optimize the curtailment assigned to the generators when ‘voltage-based’ curtailment methodology is chosen. Possible options are:
- ’cbc’
- ’glpk’
- any other available solver compatible with ‘pyomo’ such as ‘gurobi’ or ‘cplex’
Default: ‘cbc’.
- voltage_threshold (
float) – Voltage below which no curtailment is assigned to the respective generator if not necessary when ‘voltage-based’ curtailment methodology is chosen. Seeedisgo.flex_opt.curtailment.voltage_based()for more information. Default: 1.0.
- edisgo (
-
class
edisgo.grid.network.StorageControl(edisgo, timeseries, position, **kwargs)[source]¶ Bases:
objectIntegrates storages into the grid.
Parameters: - edisgo (
EDisGo) – - timeseries (
stror pandas.Series ordict) –Parameter used to obtain time series of active power the storage(s) is/are charged (negative) or discharged (positive) with. Can either be a given time series or an operation strategy. Possible options are:
- pandas.Series
Time series the storage will be charged and discharged with can be
set directly by providing a pandas.Series with
time series of active charge (negative) and discharge (positive)
power in kW. Index needs to be a
pandas.DatetimeIndex.
If no nominal power for the storage is provided in
parameters parameter, the maximum of the time series is
used as nominal power.
In case of more than one storage provide a
dictwhere each entry represents a storage. Keys of the dictionary have to match the keys of the parameters dictionary, values must contain the corresponding time series as pandas.Series. - ’fifty-fifty’ Storage operation depends on actual power of generators. If cumulative generation exceeds 50% of the nominal power, the storage will charge. Otherwise, the storage will discharge. If you choose this option you have to provide a nominal power for the storage. See parameters for more information.
Default: None.
- pandas.Series
Time series the storage will be charged and discharged with can be
set directly by providing a pandas.Series with
time series of active charge (negative) and discharge (positive)
power in kW. Index needs to be a
pandas.DatetimeIndex.
If no nominal power for the storage is provided in
parameters parameter, the maximum of the time series is
used as nominal power.
In case of more than one storage provide a
- position (None or
strorStationorBranchTeeorGeneratororLoadordict) –To position the storage a positioning strategy can be used or a node in the grid can be directly specified. Possible options are:
- ’hvmv_substation_busbar’ Places a storage unit directly at the HV/MV station’s bus bar.
StationorBranchTeeorGeneratororLoadSpecifies a node the storage should be connected to. In the case this parameter is of typeLVStationan additional parameter, voltage_level, has to be provided to define which side of the LV station the storage is connected to.- ’distribute_storages_mv’ Places one storage in each MV feeder if it reduces grid expansion costs. This method needs a given time series of active power. ToDo: Elaborate
In case of more than one storage provide a
dictwhere each entry represents a storage. Keys of the dictionary have to match the keys of the timeseries and parameters dictionaries, values must contain the corresponding positioning strategy or node to connect the storage to. - parameters (
dict, optional) –Dictionary with the following optional storage parameters:
{ 'nominal_power': <float>, # in kW 'max_hours': <float>, # in h 'soc_initial': <float>, # in kWh 'efficiency_in': <float>, # in per unit 0..1 'efficiency_out': <float>, # in per unit 0..1 'standing_loss': <float> # in per unit 0..1 }
See
Storagefor more information on storage parameters. In case of more than one storage provide adictwhere each entry represents a storage. Keys of the dictionary have to match the keys of the timeseries dictionary, values must contain the corresponding parameters dictionary specified above. Note: As edisgo currently only provides a power flow analysis storage parameters don’t have any effect on the calculations, except of the nominal power of the storage. Default: {}. - voltage_level (
strordict, optional) – This parameter only needs to be provided if any entry in position is of typeLVStation. In that case voltage_level defines which side of the LV station the storage is connected to. Valid options are ‘lv’ and ‘mv’. In case of more than one storage provide adictspecifying the voltage level for each storage that is to be connected to an LV station. Keys of the dictionary have to match the keys of the timeseries dictionary, values must contain the corresponding voltage level. Default: None. - timeseries_reactive_power (pandas.Series or
dict) – By default reactive power is set through the config file config_timeseries in sections reactive_power_factor specifying the power factor and reactive_power_mode specifying if inductive or capacitive reactive power is provided. If you want to over-write this behavior you can provide a reactive power time series in kvar here. Be aware that eDisGo uses the generator sign convention for storages (see Definitions and units section of the documentation for more information). Index of the series needs to be a pandas.DatetimeIndex. In case of more than one storage provide adictwhere each entry represents a storage. Keys of the dictionary have to match the keys of the timeseries dictionary, values must contain the corresponding time series as pandas.Series.
- edisgo (
-
class
edisgo.grid.network.TimeSeries(network, **kwargs)[source]¶ Bases:
objectDefines time series for all loads and generators in network (if set).
Contains time series for loads (sector-specific), generators (technology-specific), and curtailment (technology-specific).
-
generation_fluctuating¶ DataFrame with active power feed-in time series for fluctuating renewables solar and wind, normalized with corresponding capacity. Time series can either be aggregated by technology type or by type and weather cell ID. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID. Default: None.
Type: pandas.DataFrame, optional
-
generation_dispatchable¶ DataFrame with time series for active power of each (aggregated) type of dispatchable generator normalized with corresponding capacity. Columns represent generator type:
- ‘gas’
- ‘coal’
- ‘biomass’
- ‘other’
- …
Use ‘other’ if you don’t want to explicitly provide every possible type. Default: None.
Type: pandas.DataFrame, optional
-
generation_reactive_power¶ DataFrame with reactive power per technology and weather cell ID, normalized with the nominal active power. Time series can either be aggregated by technology type or by type and weather cell ID. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID. If the technology doesn’t contain weather cell information, i.e. if it is other than solar or wind generation, this second level can be left as a numpy Nan or a None. Default: None.
Type: pandas: pandasDataFrame<dataframe>, optional
-
load¶ DataFrame with active power of load time series of each (cumulative) type of load, normalized with corresponding annual energy demand. Columns represent load type:
- ‘residential’
- ‘retail’
- ‘industrial’
- ‘agricultural’
Default: None.Type: pandas.DataFrame, optional
-
load_reactive_power¶ DataFrame with time series of normalized reactive power (normalized by annual energy demand) per load sector. Index needs to be a pandas.DatetimeIndex. Columns represent load type:
- ‘residential’
- ‘retail’
- ‘industrial’
- ‘agricultural’
Default: None.
Type: pandas.DataFrame, optional
-
curtailment¶ In the case curtailment is applied to all fluctuating renewables this needs to be a DataFrame with active power curtailment time series. Time series can either be aggregated by technology type or by type and weather cell ID. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID. In the case curtailment is only applied to specific generators, this parameter needs to be a list of all generators that are curtailed. Default: None.
Type: pandas.DataFrame or List, optional
-
timeindex¶ Can be used to define a time range for which to obtain the provided time series and run power flow analysis. Default: None.
Type: pandas.DatetimeIndex, optional
See also
timeseries getter in
Generator,GeneratorFluctuatingandLoad.-
generation_dispatchable Get generation time series of dispatchable generators (only active power)
Returns: See class definition for details. Return type: pandas.DataFrame
-
generation_fluctuating Get generation time series of fluctuating renewables (only active power)
Returns: See class definition for details. Return type: pandas.DataFrame
-
generation_reactive_power Get reactive power time series for generators normalized by nominal active power.
Returns: See class definition for details. Return type: pandas: pandas.DataFrame<dataframe>
-
load Get load time series (only active power)
Returns: See class definition for details. Return type: dict or pandas.DataFrame
-
load_reactive_power Get reactive power time series for load normalized by annual consumption.
Returns: See class definition for details. Return type: pandas: pandas.DataFrame<dataframe>
-
timeindex param time_range: Time range of power flow analysis :type time_range: pandas.DatetimeIndex
Returns: See class definition for details. Return type: pandas.DatetimeIndex
-
curtailment Get curtailment time series of dispatchable generators (only active power)
Parameters: curtailment (list or pandas.DataFrame) – See class definition for details. Returns: In the case curtailment is applied to all solar and wind generators curtailment time series either aggregated by technology type or by type and weather cell ID are returnded. In the first case columns of the DataFrame are ‘solar’ and ‘wind’; in the second case columns need to be a pandas.MultiIndex with the first level containing the type and the second level the weather cell ID. In the case curtailment is only applied to specific generators, curtailment time series of all curtailed generators, specified in by the column name are returned. Return type: pandas.DataFrame
-
timesteps_load_feedin_case¶ Contains residual load and information on feed-in and load case.
Residual load is calculated from total (load - generation) in the grid. Grid losses are not considered.
Feed-in and load case are identified based on the generation and load time series and defined as follows:
- Load case: positive (load - generation) at HV/MV substation
- Feed-in case: negative (load - generation) at HV/MV substation
See also
assign_load_feedin_case().Parameters: timeseries_load_feedin_case (pandas.DataFrame) – Dataframe with information on whether time step is handled as load case (‘load_case’) or feed-in case (‘feedin_case’) for each time step in timeindex. Index of the series is thetimeindex.Returns: Series with information on whether time step is handled as load case (‘load_case’) or feed-in case (‘feedin_case’) for each time step in timeindex. Index of the dataframe istimeindex. Columns of the dataframe are ‘residual_load’ with (load - generation) in kW at HV/MV substation and ‘case’ with ‘load_case’ for positive residual load and ‘feedin_case’ for negative residual load.Return type: pandas.Series
-
-
class
edisgo.grid.network.Results(network)[source]¶ Bases:
objectPower flow analysis results management
Includes raw power flow analysis results, history of measures to increase the grid’s hosting capacity and information about changes of equipment.
-
measures¶ List with the history of measures to increase grid’s hosting capacity.
Parameters: measure ( str) – Measure to increase grid’s hosting capacity. Possible options are ‘grid_expansion’, ‘storage_integration’, ‘curtailment’.Returns: measures – A stack that details the history of measures to increase grid’s hosting capacity. The last item refers to the latest measure. The key original refers to the state of the grid topology as it was initially imported. Return type: list
-
pfa_p¶ Active power results from power flow analysis in kW.
Holds power flow analysis results for active power for the last iteration step. Index of the DataFrame is a DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the DataFrame are the edges as well as stations of the grid topology.
Parameters: pypsa (pandas.DataFrame) – Results time series of active power P in kW from the PyPSA network
Provide this if you want to set values. For retrieval of data do not pass an argument
Returns: Active power results from power flow analysis Return type: pandas.DataFrame
-
pfa_q¶ Reactive power results from power flow analysis in kvar.
Holds power flow analysis results for reactive power for the last iteration step. Index of the DataFrame is a DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the DataFrame are the edges as well as stations of the grid topology.
Parameters: pypsa (pandas.DataFrame) – Results time series of reactive power Q in kvar from the PyPSA network
Provide this if you want to set values. For retrieval of data do not pass an argument
Returns: Reactive power results from power flow analysis Return type: pandas.DataFrame
-
pfa_v_mag_pu¶ Voltage deviation at node in p.u.
Holds power flow analysis results for relative voltage deviation for the last iteration step. Index of the DataFrame is a DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the DataFrame are the nodes as well as stations of the grid topology.
Parameters: pypsa (pandas.DataFrame) – Results time series of voltage deviation in p.u. from the PyPSA network
Provide this if you want to set values. For retrieval of data do not pass an argument
Returns: Voltage level nodes of grid Return type: pandas.DataFrame
-
i_res¶ Current results from power flow analysis in A.
Holds power flow analysis results for current for the last iteration step. Index of the DataFrame is a DatetimeIndex indicating the time period the power flow analysis was conducted for; columns of the DataFrame are the edges as well as stations of the grid topology.
Parameters: pypsa (pandas.DataFrame) – Results time series of current in A from the PyPSA network
Provide this if you want to set values. For retrieval of data do not pass an argument
Returns: Current results from power flow analysis Return type: pandas.DataFrame
-
equipment_changes¶ Tracks changes in the equipment (e.g. replaced or added cable, etc.)
The DataFrame is indexed by the component(
Line,Station, etc.) and has the following columns:equipment : detailing what was changed (line, station, storage, curtailment). For ease of referencing we take the component itself. For lines we take the line-dict, for stations the transformers, for storages the storage-object itself and for curtailment either a dict providing the details of curtailment or a curtailment object if this makes more sense (has to be defined).
- change :
str - Specifies if something was added or removed.
- iteration_step :
int - Used for the update of the pypsa network to only consider changes since the last power flow analysis.
- quantity :
int - Number of components added or removed. Only relevant for calculation of grid expansion costs to keep track of how many new standard lines were added.
Parameters: changes (pandas.DataFrame) – Provide this if you want to set values. For retrieval of data do not pass an argument. Returns: Equipment changes Return type: pandas.DataFrame - change :
-
grid_expansion_costs¶ Holds grid expansion costs in kEUR due to grid expansion measures tracked in self.equipment_changes and calculated in edisgo.flex_opt.costs.grid_expansion_costs()
Parameters: total_costs (pandas.DataFrame) – DataFrame containing type and costs plus in the case of lines the line length and number of parallel lines of each reinforced transformer and line. Provide this if you want to set grid_expansion_costs. For retrieval of costs do not pass an argument.
Index of the DataFrame is the respective object that can either be a
Lineor aTransformer. Columns are the following:- type :
str - Transformer size or cable name
- total_costs :
float - Costs of equipment in kEUR. For lines the line length and number of parallel lines is already included in the total costs.
- quantity :
int - For transformers quantity is always one, for lines it specifies the number of parallel lines.
- line_length :
float - Length of line or in case of parallel lines all lines in km.
- voltage_level :
str - Specifies voltage level the equipment is in (‘lv’, ‘mv’ or ‘mv/lv’).
- mv_feeder :
Line - First line segment of half-ring used to identify in which feeder the grid expansion was conducted in.
Returns: Costs of each reinforced equipment in kEUR. Return type: pandas.DataFrame Notes
Total grid expansion costs can be obtained through costs.total_costs.sum().
- type :
-
grid_losses¶ Holds active and reactive grid losses in kW and kvar, respectively.
Parameters: pypsa_grid_losses (pandas.DataFrame) – Dataframe holding active and reactive grid losses in columns ‘p’ and ‘q’ and in kW and kvar, respectively. Index is a pandas.DatetimeIndex. Returns: Dataframe holding active and reactive grid losses in columns ‘p’ and ‘q’ and in kW and kvar, respectively. Index is a pandas.DatetimeIndex. Return type: pandas.DataFrame Notes
Grid losses are calculated as follows:
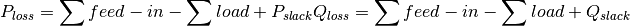
As the slack is placed at the secondary side of the HV/MV station losses do not include losses of the HV/MV transformers.
-
hv_mv_exchanges¶ Holds active and reactive power exchanged with the HV grid.
The exchanges are essentially the slack results. As the slack is placed at the secondary side of the HV/MV station, this gives the energy transferred to and taken from the HV grid at the secondary side of the HV/MV station.
Parameters: hv_mv_exchanges (pandas.DataFrame) – Dataframe holding active and reactive power exchanged with the HV grid in columns ‘p’ and ‘q’ and in kW and kvar, respectively. Index is a pandas.DatetimeIndex. Returns: Dataframe holding active and reactive power exchanged with the HV grid in columns ‘p’ and ‘q’ and in kW and kvar, respectively. Index is a pandas.DatetimeIndex. Return type: pandas:`pandas.DataFrame<dataframe>
-
curtailment¶ Holds curtailment assigned to each generator per curtailment target.
Returns: Keys of the dictionary are generator types (and weather cell ID) curtailment targets were given for. E.g. if curtailment is provided as a pandas.DataFrame with :pandas.`pandas.MultiIndex` columns with levels ‘type’ and ‘weather cell ID’ the dictionary key is a tuple of (‘type’,’weather_cell_id’). Values of the dictionary are dataframes with the curtailed power in kW per generator and time step. Index of the dataframe is a pandas.DatetimeIndex. Columns are the generators of type edisgo.grid.components.GeneratorFluctuating.Return type: dictwith pandas.DataFrame
-
storages¶ Gathers relevant storage results.
Returns: Dataframe containing all storages installed in the MV grid and LV grids. Index of the dataframe are the storage representatives, columns are the following: Return type: pandas.DataFrame
-
storages_timeseries()[source]¶ Returns a dataframe with storage time series.
Returns: Dataframe containing time series of all storages installed in the MV grid and LV grids. Index of the dataframe is a pandas.DatetimeIndex. Columns are the storage representatives. Return type: pandas.DataFrame
-
storages_costs_reduction¶ Contains costs reduction due to storage integration.
Parameters: costs_df (pandas.DataFrame) – Dataframe containing grid expansion costs in kEUR before and after storage integration in columns ‘grid_expansion_costs_initial’ and ‘grid_expansion_costs_with_storages’, respectively. Index of the dataframe is the MV grid id. Returns: Dataframe containing grid expansion costs in kEUR before and after storage integration in columns ‘grid_expansion_costs_initial’ and ‘grid_expansion_costs_with_storages’, respectively. Index of the dataframe is the MV grid id. Return type: pandas.DataFrame
-
unresolved_issues¶ Holds lines and nodes where over-loading or over-voltage issues could not be solved in grid reinforcement.
In case over-loading or over-voltage issues could not be solved after maximum number of iterations, grid reinforcement is not aborted but grid expansion costs are still calculated and unresolved issues listed here.
Parameters: issues (dict) – Dictionary of critical lines/stations with relative over-loading and critical nodes with voltage deviation in p.u.. Format:
{crit_line_1: rel_overloading_1, ..., crit_line_n: rel_overloading_n, crit_node_1: v_mag_pu_node_1, ..., crit_node_n: v_mag_pu_node_n}
Provide this if you want to set unresolved_issues. For retrieval of unresolved issues do not pass an argument.
Returns: Dictionary of critical lines/stations with relative over-loading and critical nodes with voltage deviation in p.u. Return type: Dictionary
-
s_res(components=None)[source]¶ Get resulting apparent power in kVA at line(s) and transformer(s).
The apparent power at a line (or transformer) is determined from the maximum values of active power P and reactive power Q.
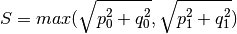
Parameters: components ( list) – List with all components (of typeLineorTransformer) to get apparent power for. If not provided defaults to return apparent power of all lines and transformers in the grid.Returns: Apparent power in kVA for lines and/or transformers. Return type: pandas.DataFrame
-
v_res(nodes=None, level=None)[source]¶ Get voltage results (in p.u.) from power flow analysis.
Parameters: - nodes (
Load,Generator, etc. orlist) – Grid topology component or list of grid topology components. If not provided defaults to column names available in grid level level. - level (str) – Either ‘mv’ or ‘lv’ or None (default). Depending on which grid level results you are interested in. It is required to provide this argument in order to distinguish voltage levels at primary and secondary side of the transformer/LV station. If not provided (respectively None) defaults to [‘mv’, ‘lv’].
Returns: Resulting voltage levels obtained from power flow analysis
Return type: Notes
Limitation: When power flow analysis is performed for MV only (with aggregated LV loads and generators) this methods only returns voltage at secondary side busbar and not at load/generator.
- nodes (
-
save(directory, parameters='all')[source]¶ Saves results to disk.
Depending on which results are selected and if they exist, the following directories and files are created:
powerflow_results directory
voltages_pu.csv
See
pfa_v_mag_pufor more information.currents.csv
See
i_res()for more information.active_powers.csv
See
pfa_pfor more information.reactive_powers.csv
See
pfa_qfor more information.apparent_powers.csv
See
s_res()for more information.grid_losses.csv
See
grid_lossesfor more information.hv_mv_exchanges.csv
See
hv_mv_exchangesfor more information.
pypsa_network directory
See
pypsa.Network.export_to_csv_folder()grid_expansion_results directory
grid_expansion_costs.csv
See
grid_expansion_costsfor more information.equipment_changes.csv
See
equipment_changesfor more information.unresolved_issues.csv
See
unresolved_issuesfor more information.
curtailment_results directory
Files depend on curtailment specifications. There will be one file for each curtailment specification, that is for every key in
curtailmentdictionary.storage_integration_results directory
storages.csv
See
storages()for more information.
Parameters: - directory (
str) – Directory to save the results in. - parameters (
strorlistofstr) –Specifies which results will be saved. By default all results are saved. To only save certain results set parameters to one of the following options or choose several options by providing a list:
- ’pypsa_network’
- ’powerflow_results’
- ’grid_expansion_results’
- ’curtailment_results’
- ’storage_integration_results’
-
-
class
edisgo.grid.network.NetworkReimport(results_path, **kwargs)[source]¶ Bases:
objectNetwork class created from saved results.
-
class
edisgo.grid.network.ResultsReimport(results_path, parameters='all')[source]¶ Bases:
objectResults class created from saved results.
-
v_res(nodes=None, level=None)[source]¶ Get resulting voltage level at node.
Parameters: - nodes (
list) – List of string representatives of grid topology components, e.g.Generator. If not provided defaults to all nodes available in grid level level. - level (
str) – Either ‘mv’ or ‘lv’ or None (default). Depending on which grid level results you are interested in. It is required to provide this argument in order to distinguish voltage levels at primary and secondary side of the transformer/LV station. If not provided (respectively None) defaults to [‘mv’, ‘lv’].
Returns: Resulting voltage levels obtained from power flow analysis
Return type: - nodes (
-
s_res(components=None)[source]¶ Get apparent power in kVA at line(s) and transformer(s).
Parameters: components ( list) – List of string representatives ofLineorTransformer. If not provided defaults to return apparent power of all lines and transformers in the grid.Returns: Apparent power in kVA for lines and/or transformers. Return type: pandas.DataFrame
-
storages_timeseries()[source]¶ Returns a dataframe with storage time series.
Returns: Dataframe containing time series of all storages installed in the MV grid and LV grids. Index of the dataframe is a pandas.DatetimeIndex. Columns are the storage representatives. Return type: pandas.DataFrame
-
edisgo.grid.tools module¶
-
edisgo.grid.tools.position_switch_disconnectors(mv_grid, mode='load', status='open')[source]¶ Determine position of switch disconnector in MV grid rings
Determination of the switch disconnector location is motivated by placing it to minimized load flows in both parts of the ring (half-rings). The switch disconnecter will be installed to a LV station, unless none exists in a ring. In this case, a node of arbitrary type is chosen for the location of the switch disconnecter.
Parameters: - mv_grid (
MVGrid) – MV grid instance - mode (str) – Define modus switch disconnector positioning: can be performed based of ‘load’, ‘generation’ or both ‘loadgen’. Defaults to ‘load’
- status (str) – Either ‘open’ or ‘closed’. Define which status is should be set initially. Defaults to ‘open’ (which refers to conditions of normal grid operation).
Returns: A tuple of size 2 specifying their pair of nodes between which the switch disconnector is located. The first node specifies the node that actually includes the switch disconnector.
Return type: Notes
This function uses nx.algorithms.find_cycle() to identify nodes that are part of the MV grid ring(s). Make sure grid topology data that is provided has closed rings. Otherwise, no location for a switch disconnector can be identified.
- mv_grid (
-
edisgo.grid.tools.implement_switch_disconnector(mv_grid, node1, node2)[source]¶ Install switch disconnector in grid topology
The graph that represents the grid’s topology is altered in such way that it explicitly includes a switch disconnector. The switch disconnector is always located at
node1. Technically, it does not make any difference. This is just an convention ensuring consistency of multiple runs.The ring is still closed after manipulations of this function.
Parameters: - mv_grid (
MVGrid) – MV grid instance - node1 – A rings node
- node2 – Another rings node
- mv_grid (
-
edisgo.grid.tools.select_cable(network, level, apparent_power)[source]¶ Selects an appropriate cable type and quantity using given apparent power.
Considers load factor.
Parameters: Returns: - pandas.Series – Cable type
ìnt– Cable count
Notes
Cable is selected to be able to carry the given apparent_power, no load factor is considered.
-
edisgo.grid.tools.get_gen_info(network, level='mvlv', fluctuating=False)[source]¶ Gets all the installed generators with some additional information.
Parameters: - network (
Network) – Network object holding the grid data. - level (
str) –Defines which generators are returned. Possible options are:
- ’mv’ Only generators connected to the MV grid are returned.
- ’lv’ Only generators connected to the LV grids are returned.
- ’mvlv’ All generators connected to the MV grid and LV grids are returned.
Default: ‘mvlv’.
- fluctuating (
bool) – If True only returns fluctuating generators. Default: False.
Returns: Dataframe with all generators connected to the specified voltage level. Index of the dataframe are the generator objects of type
Generator. Columns of the dataframe are:- ’gen_repr’
The representative of the generator as
str. - ’type’
The generator type, e.g. ‘solar’ or ‘wind’ as
str. - ’voltage_level’
The voltage level the generator is connected to as
str. Can either be ‘mv’ or ‘lv’. - ’nominal_capacity’
The nominal capacity of the generator as as
float. - ’weather_cell_id’
The id of the weather cell the generator is located in as
int(only applies to fluctuating generators).
Return type: - network (
-
edisgo.grid.tools.assign_mv_feeder_to_nodes(mv_grid)[source]¶ Assigns an MV feeder to every generator, LV station, load, and branch tee
Parameters: mv_grid ( MVGrid) –
-
edisgo.grid.tools.get_mv_feeder_from_line(line)[source]¶ Determines MV feeder the given line is in.
MV feeders are identified by the first line segment of the half-ring.
Parameters: line ( Line) – Line to find the MV feeder for.Returns: MV feeder identifier (representative of the first line segment of the half-ring) Return type: Line