edisgo.io package¶
edisgo.io.ding0_import module¶
- edisgo.io.ding0_import.import_ding0_grid(path, edisgo_obj)[source]¶
Import an eDisGo network topology from Ding0 data.
This import method is specifically designed to load network topology data in the format as Ding0 provides it via csv files.
- edisgo.io.ding0_import.remove_1m_end_lines(edisgo)[source]¶
Method to remove 1m end lines to reduce size of edisgo object.
Short lines inside houses are removed in this function, including the end node. Components that were originally connected to the end node are reconnected to the upstream node.
This function will become obsolete once it is changed in the ding0 export.
edisgo.io.electromobility_import module¶
- edisgo.io.electromobility_import.import_electromobility(edisgo_obj, simbev_directory, tracbev_directory, **kwargs)[source]¶
Import electromobility data from SimBEV and TracBEV.
- Parameters
edisgo_obj (
EDisGo) –simbev_directory (str or pathlib.PurePath) – SimBEV directory holding SimBEV data.
tracbev_directory (str or pathlib.PurePath) – TracBEV directory holding TracBEV data.
kwargs –
Kwargs may contain any further attributes you want to specify.
- gc_to_car_rate_homefloat
Specifies the minimum rate between potential charging parks points for the use case “home” and the total number of cars. Default 0.5 .
- gc_to_car_rate_workfloat
Specifies the minimum rate between potential charging parks points for the use case “work” and the total number of cars. Default 0.25 .
- gc_to_car_rate_publicfloat
Specifies the minimum rate between potential charging parks points for the use case “public” and the total number of cars. Default 0.1 .
- gc_to_car_rate_hpcfloat
Specifies the minimum rate between potential charging parks points for the use case “hpc” and the total number of cars. Default 0.005 .
- mode_parking_timesstr
If the mode_parking_times is set to “frugal” only parking times with any charging demand are imported. Default “frugal”.
- charging_processes_dirstr
Charging processes sub-directory. Default None.
- simbev_config_filestr
Name of the simbev config file. Default “metadata_simbev_run.json”.
- edisgo.io.electromobility_import.read_csvs_charging_processes(csv_path, mode='frugal', csv_dir=None)[source]¶
Reads all CSVs in a given path and returns a DataFrame with all SimBEV charging processes.
- Parameters
- Returns
DataFrame with AGS, car ID, trip destination, charging use case (private or public), netto charging capacity, charging demand, charge start, charge end, potential charging park ID and charging point ID.
- Return type
- edisgo.io.electromobility_import.read_simbev_config_df(path, edisgo_obj, simbev_config_file='metadata_simbev_run.json')[source]¶
Get SimBEV config data.
- Parameters
- Returns
DataFrame with used random seed, used threads, stepsize in minutes, year, scenarette, simulated days, maximum number of cars per AGS, completed standing times and time series per AGS and used ramp up data CSV.
- Return type
- edisgo.io.electromobility_import.read_gpkg_potential_charging_parks(path, edisgo_obj, **kwargs)[source]¶
Get GeoDataFrame with all TracBEV potential charging parks.
- Parameters
- Returns
GeoDataFrame with AGS, charging use case (home, work, public or hpc), user centric weight and geometry.
- Return type
- edisgo.io.electromobility_import.distribute_charging_demand(edisgo_obj, **kwargs)[source]¶
Distribute charging demand from SimBEV onto potential charging parks from TracBEV.
- Parameters
edisgo_obj (
EDisGo) –kwargs –
Kwargs may contain any further attributes you want to specify.
- modestr
Distribution mode. If the mode is set to “user_friendly” only the simbev weights are used for the distribution. If the mode is “grid_friendly” also grid conditions are respected. Default “user_friendly”.
- generators_weight_factorfloat
Weighting factor of the generators weight within an LV grid in comparison to the loads weight. Default 0.5.
- distance_weightfloat
Weighting factor for the distance between a potential charging park and its nearest substation in comparison to the combination of the generators and load factors of the LV grids. Default 1 / 3.
- user_friendly_weightfloat
Weighting factor of the user friendly weight in comparison to the grid friendly weight. Default 0.5.
- edisgo.io.electromobility_import.get_weights_df(edisgo_obj, potential_charging_park_indices, **kwargs)[source]¶
Get weights per potential charging point for a given set of grid connection indices.
- Parameters
edisgo_obj (
EDisGo) –potential_charging_park_indices (list) – List of potential charging parks indices
mode (str) – Only use user friendly weights (“user_friendly”) or combine with grid friendly weights (“grid_friendly”). Default: “user_friendly”.
user_friendly_weight (float) – Weight of user friendly weight if mode “grid_friendly”. Default: 0.5.
distance_weight (float) – Grid friendly weight is a combination of the installed capacity of generators and loads within a LV grid and the distance towards the nearest substation. This parameter sets the weight for the distance parameter. Default: 1/3.
- Returns
DataFrame with numeric weights
- Return type
- edisgo.io.electromobility_import.normalize(weights_df)[source]¶
Normalize a given DataFrame so that its sum equals 1 and return a flattened Array.
- Parameters
weights_df (pandas.DataFrame) – DataFrame with single numeric column
- Returns
Array with normalized weights
- Return type
Numpy 1-D array
- edisgo.io.electromobility_import.combine_weights(potential_charging_park_indices, designated_charging_point_capacity_df, weights_df)[source]¶
Add designated charging capacity weights into the initial weights and normalize weights
- Parameters
potential_charging_park_indices (list) – List of potential charging parks indices
designated_charging_point_capacity_df – pandas.DataFrame DataFrame with designated charging point capacity per potential charging park
weights_df (pandas.DataFrame) – DataFrame with initial user or combined weights
- Returns
Array with normalized weights
- Return type
Numpy 1-D array
- edisgo.io.electromobility_import.weighted_random_choice(edisgo_obj, potential_charging_park_indices, car_id, destination, charging_point_id, normalized_weights, rng=None)[source]¶
Weighted random choice of a potential charging park. Setting the chosen values into
charging_processes_df- Parameters
edisgo_obj (
EDisGo) –potential_charging_park_indices (list) – List of potential charging parks indices
car_id (int) – Car ID
destination (str) – Trip destination
charging_point_id (int) – Charging Point ID
normalized_weights (Numpy 1-D array) – Array with normalized weights
rng (Numpy random generator) – If None a random generator with seed=charging_point_id is initialized
- Returns
Chosen Charging Park ID
- Return type
- edisgo.io.electromobility_import.distribute_private_charging_demand(edisgo_obj)[source]¶
Distributes all private charging processes. Each car gets its own private charging point if a charging process takes place.
- Parameters
edisgo_obj (
EDisGo) –
- edisgo.io.electromobility_import.distribute_public_charging_demand(edisgo_obj, **kwargs)[source]¶
Distributes all public charging processes. For each process it is checked if a matching charging point exists to minimize the number of charging points.
- Parameters
edisgo_obj (
EDisGo) –
edisgo.io.generators_import module¶
- edisgo.io.generators_import.oedb(edisgo_object, generator_scenario, **kwargs)[source]¶
Gets generator park for specified scenario from oedb and integrates them into the grid.
The importer uses SQLAlchemy ORM objects. These are defined in ego.io.
For further information see also
import_generators.- Parameters
edisgo_object (
EDisGo) –generator_scenario (str) – Scenario for which to retrieve generator data. Possible options are ‘nep2035’ and ‘ego100’.
remove_decommissioned (bool) – If True, removes generators from network that are not included in the imported dataset (=decommissioned). Default: True.
update_existing (bool) – If True, updates capacity of already existing generators to capacity specified in the imported dataset. Default: True.
p_target (dict or None) – Per default, no target capacity is specified and generators are expanded as specified in the respective scenario. However, you may want to use one of the scenarios but have slightly more or less generation capacity than given in the respective scenario. In that case you can specify the desired target capacity per technology type using this input parameter. The target capacity dictionary must have technology types (e.g. ‘wind’ or ‘solar’) as keys and corresponding target capacities in MW as values. If a target capacity is given that is smaller than the total capacity of all generators of that type in the future scenario, only some of the generators in the future scenario generator park are installed, until the target capacity is reached. If the given target capacity is greater than that of all generators of that type in the future scenario, then each generator capacity is scaled up to reach the target capacity. Be careful to not have much greater target capacities as this will lead to unplausible generation capacities being connected to the different voltage levels. Also be aware that only technologies specified in the dictionary are expanded. Other technologies are kept the same. Default: None.
allowed_number_of_comp_per_lv_bus (int) – Specifies, how many generators are at most allowed to be placed at the same LV bus. Default: 2.
edisgo.io.pypsa_io module¶
This module provides tools to convert eDisGo representation of the network
topology to PyPSA data model. Call to_pypsa() to retrieve the PyPSA network
container.
- edisgo.io.pypsa_io.to_pypsa(edisgo_object, mode=None, timesteps=None, **kwargs)[source]¶
Convert grid to PyPSA.Network representation.
You can choose between translation of the MV and all underlying LV grids (mode=None (default)), the MV network only (mode=’mv’ or mode=’mvlv’) or a single LV network (mode=’lv’).
- Parameters
edisgo_object (
EDisGo) – EDisGo object containing grid topology and time series information.mode (str) – Determines network levels that are translated to PyPSA.Network. See mode parameter in
to_pypsafor more information.timesteps (pandas.DatetimeIndex or pandas.Timestamp) – See timesteps parameter in
to_pypsafor more information.
:param See other parameters in
to_pypsafor more: :param information.:- Returns
PyPSA.Network representation.
- Return type
- edisgo.io.pypsa_io.set_seed(edisgo_obj, pypsa_network)[source]¶
Set initial guess for the Newton-Raphson algorithm.
In PyPSA an initial guess for the Newton-Raphson algorithm used in the power flow analysis can be provided to speed up calculations. For PQ buses, which besides the slack bus, is the only bus type in edisgo, voltage magnitude and angle need to be guessed. If the power flow was already conducted for the required time steps and buses, the voltage magnitude and angle results from previously conducted power flows stored in
pfa_v_mag_pu_seedandpfa_v_ang_seedare used as the initial guess. Always the latest power flow calculation is used and only results from power flow analyses including the MV level are considered, as analysing single LV grids is currently not in the focus of edisgo and does not require as much speeding up, as analysing single LV grids is usually already quite quick. If for some buses or time steps no power flow results are available, default values are used. For the voltage magnitude the default value is 1 and for the voltage angle 0.- Parameters
edisgo_obj (
EDisGo) –pypsa_network (pypsa.Network) – Pypsa network in which seed is set.
- edisgo.io.pypsa_io.process_pfa_results(edisgo, pypsa, timesteps, dtype='float')[source]¶
Passing power flow results from PyPSA to
Results.- Parameters
edisgo (
EDisGo) –pypsa (pypsa.Network) – The PyPSA Network container
timesteps (pandas.DatetimeIndex or pandas.Timestamp) – Time steps for which latest power flow analysis was conducted and for which to retrieve pypsa results.
Notes
P and Q are returned from the line ending/transformer side with highest apparent power S, exemplary written as
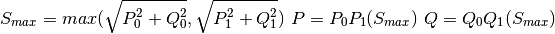
See also
Results,analysis
edisgo.io.timeseries_import module¶
- edisgo.io.timeseries_import.feedin_oedb(config_data, weather_cell_ids, timeindex)[source]¶
Import feed-in time series data for wind and solar power plants from the OpenEnergy DataBase.
- Parameters
config_data (
Config) – Configuration data from config files, relevant for information of which data base table to retrieve feed-in data from.weather_cell_ids (list(int)) – List of weather cell id’s (integers) to obtain feed-in data for.
timeindex (pandas.DatetimeIndex) – Feed-in data is currently only provided for weather year 2011. If timeindex contains a different year, the data is reindexed.
- Returns
DataFrame with hourly time series for active power feed-in per generator type (wind or solar, in column level 0) and weather cell (in column level 1), normalized to a capacity of 1 MW.
- Return type
- edisgo.io.timeseries_import.load_time_series_demandlib(config_data, timeindex)[source]¶
Get normalized sectoral electricity load time series using the demandlib.
Resulting electricity load profiles hold time series of hourly conventional electricity demand for the sectors residential, retail, agricultural and industrial. Time series are normalized to a consumption of 1 MWh per year.
- Parameters
config_data (
Config) – Configuration data from config files, relevant for industrial load profiles.timeindex (pandas.DatetimeIndex) – Timesteps for which to generate load time series.
- Returns
DataFrame with conventional electricity load time series for sectors residential, retail, agricultural and industrial. Index is a pandas.DatetimeIndex. Columns hold the sector type.
- Return type
- edisgo.io.timeseries_import.cop_oedb(config_data, weather_cell_ids=None, timeindex=None)[source]¶
Get COP (coefficient of performance) time series data from the OpenEnergy DataBase.
- Parameters
config_data (
Config) – Configuration data from config files, relevant for information of which data base table to retrieve COP data from.weather_cell_ids (list(int)) – List of weather cell id’s (integers) to obtain COP data for.
timeindex (pandas.DatetimeIndex) – COP data is only provided for the weather year 2011. If timeindex contains a different year, the data is reindexed.
- Returns
DataFrame with hourly COP time series in p.u. per weather cell.
- Return type
- edisgo.io.timeseries_import.heat_demand_oedb(config_data, building_ids, timeindex=None)[source]¶
Get heat demand time series data from the OpenEnergy DataBase.
- Parameters
config_data (
Config) – Configuration data from config files, relevant for information of which data base table to retrieve data from.building_ids (list(int)) – List of building IDs to obtain heat demand for.
timeindex (pandas.DatetimeIndex) – Heat demand data is only provided for the weather year 2011. If timeindex contains a different year, the data is reindexed.
- Returns
DataFrame with hourly heat demand time series in MW per building ID.
- Return type