Usage details
As eDisGo is designed to serve as a toolbox, it provides several methods to analyze distribution grids for grid issues and to evaluate measures responding these. Below, we give a detailed introduction to the data structure and to how different features can be used.
The fundamental data structure
It’s worth understanding how the fundamental data structure of eDisGo is designed in order to make use of its entire features.
The class EDisGo serves as the top-level API for
setting up your scenario, invocation of data import, analysis of hosting
capacity, grid reinforcement and flexibility measures. It also provides
access to all relevant data.
Grid data is stored in the Topology class.
Time series data can be found in the TimeSeries
class.
The class Electromobility holds data on charging
processes (how long cars are parking at a charging station, how much they need to charge,
etc.) necessary to apply different charging strategies, as well as information on
potential charging sites and integrated charging parks.
The class HeatPump holds data on
heat pump COP, heat demand to be served by the heat pumps and thermal storage units, which is
necessary to determine flexibility potential of heat pumps.
Results data holding results e.g. from the power flow analysis and grid
expansion is stored in the Results class.
Configuration data from the config files (see Default configuration data) is stored
in the Config class.
All these can be accessed through the EDisGo object. In the following
code examples edisgo constitues an EDisGo object.
# Access Topology grid data container object
edisgo.topology
# Access TimeSeries data container object
edisgo.timeseries
# Access Electromobility data container object
edisgo.electromobility
# Access HeatPump data container object
edisgo.heat_pump
# Access Results data container object
edisgo.results
# Access configuration data container object
edisgo.config
Grid data is stored in pandas.DataFrames
in the Topology object.
There are extra data frames for all
grid elements (buses, lines, switches, transformers), as well as generators,
loads and storage units.
You can access those dataframes as follows:
# Access all buses in MV grid and underlying LV grids
edisgo.topology.buses_df
# Access all lines in MV grid and underlying LV grids
edisgo.topology.lines_df
# Access all MV/LV transformers
edisgo.topology.transformers_df
# Access all HV/MV transformers
edisgo.topology.transformers_hvmv_df
# Access all switches in MV grid and underlying LV grids
edisgo.topology.switches_df
# Access all generators in MV grid and underlying LV grids
edisgo.topology.generators_df
# Access all loads in MV grid and underlying LV grids
edisgo.topology.loads_df
# Access all storage units in MV grid and underlying LV grids
edisgo.topology.storage_units_df
The grids can also be accessed individually. The MV grid is stored in an
MVGrid object and each LV grid in an
LVGrid object.
The MV grid topology can be accessed through
# Access MV grid
edisgo.topology.mv_grid
Its components can be accessed analog to those of the whole grid topology as shown above.
# Access all buses in MV grid
edisgo.topology.mv_grid.buses_df
# Access all generators in MV grid
edisgo.topology.mv_grid.generators_df
A list of all LV grids can be retrieved through:
# Get list of all underlying LV grids
# (Note that MVGrid.lv_grids returns a generator object that must first be
# converted to a list in order to view the LVGrid objects)
list(edisgo.topology.mv_grid.lv_grids)
# the following yields the same
list(edisgo.topology.lv_grids)
Access to a single LV grid’s components can be obtained analog to shown above for the whole topology and the MV grid:
# Get single LV grid by providing its ID (e.g. 1) or name (e.g. "LVGrid_1")
lv_grid = edisgo.topology.get_lv_grid("LVGrid_402945")
# Access all buses in that LV grid
lv_grid.buses_df
# Access all loads in that LV grid
lv_grid.loads_df
A single grid’s generators, loads, storage units and switches can also be
retrieved as Generator,
Load, Storage, and
Switch objects, respecitvely:
# Get all switch disconnectors in MV grid as Switch objects
# (Note that objects are returned as a python generator object that must
# first be converted to a list in order to view the Switch objects)
list(edisgo.topology.mv_grid.switch_disconnectors)
# Get all generators in LV grid as Generator objects
list(lv_grid.generators)
For some applications it is helpful to get a graph representation of the grid, e.g. to find the path from the station to a generator. The graph representation of the whole topology or each single grid can be retrieved as follows:
# Get graph representation of whole topology
edisgo.to_graph()
# Get graph representation for MV grid
edisgo.topology.mv_grid.graph
# Get graph representation for LV grid
lv_grid.graph
The returned graph is a networkx.Graph, where lines are represented by edges in the graph, and buses and transformers are represented by nodes.
Database Connection for Loading Data from egon-data
This section describes how to connect to and load data from egon-data. There are two supported connection methods:
Using the OEP database (standard)
Using a custom PostgreSQL database
OEP Database (Standard)
The OEP database provides the egon-data interface and is the default data source.
No engine argument is required — when omitted, a default OEP engine is created
automatically. The following methods support this behaviour:
set_time_series_active_power_predefined(),
import_generators(),
import_electromobility(),
import_heat_pumps(),
import_dsm(), and
import_home_batteries().
Example
from edisgo.io.timeseries import set_time_series_active_power_predefined
edisgo_obj.set_time_series_active_power_predefined(
fluctuating_generators_ts="oedb" # use "oedb" to load data from OEP,
)
OEP Token Setup
To authenticate with OEP, place a file named OEP_TOKEN.txt in the directory edisgo/config/.
The file should contain your personal OEP access token.
A token can be requested at:
Using a OEP token is optional but recommended to avoid issues related to connection limits for anonymous users.
Using a Custom PostgreSQL Database
It is possible to connect to a custom PostgreSQL database instead of OEP. This requires a configuration file and database engine initialization.
Step 1: Create a Database Configuration File
Create a YAML configuration file (for example: database_config.yaml) with your connection parameters:
egon-data:
database-host: mydb.example.org
database-port: 5432
database-name: egon_data
database-user: my_user
database-password: my_password
ssh-tunnel:
ssh-host: my.ssh.server
ssh-user: ubuntu
ssh-pkey: ~/.ssh/id_rsa
pgres-host: localhost
If no SSH tunnel is required, the ssh-tunnel block can be left empty or removed.
Step 2: Initialize the Database Engine
The database engine can be initialized using the engine() function:
from edisgo.io.db import engine
# Path to your YAML configuration file
config_path = "path/to/database_config.yaml"
# Create the database engine
eng = engine(path=config_path, ssh=False)
Step 3: Load Data from the Custom Database
Once the engine is initialized, data can be loaded using the same functions as for OEP.
Pass the engine argument to specify your connection.
from edisgo.io.timeseries import set_time_series_active_power_predefined
edisgo_obj.set_time_series_active_power_predefined(
fluctuating_generators_ts="oedb",
engine=eng
)
This will retrieve time series or other data directly from your configured database.
Summary
Access Type |
Description |
Authentication |
|---|---|---|
OEP |
Load official egon-data source |
OEP token (recommended) |
Custom PostgreSQL database |
Connect to user-defined database |
YAML config file with credentials |
Component time series
There are various options how to set active and reactive power time series. First, options for setting active power time series are explained, followed by options for setting reactive power time series. You can also check out the A minimum working example section to get a quick start.
Active power time series
There are various options how to set active time series:
“manual”: providing your own time series
“worst-case”: using simultaneity factors from config files
“predefined”: using predefined profiles, e.g. standard load profiles
“optimised”: using the LOPF to optimise e.g. vehicle charging
“heuristic”: using heuristics
Manual
Use this mode to provide your own time series for specific components. It can be invoked as follows:
edisgo.set_time_series_manual()
See set_time_series_manual for more information.
When using this mode make sure to previously set the time index. This can either be done
upon initialisation of the EDisGo object by providing the input parameter ‘timeindex’ or
by using the function set_timeindex.
Worst-case
Use this mode to set feed-in and load in heavy load flow case (here called “load_case”) and/or reverse power flow case (here called “feed-in_case”) using simultaneity factors used in conventional grid planning. It can be invoked as follows:
edisgo.set_time_series_worst_case_analysis()
See set_time_series_worst_case_analysis for more information.
When using this mode a fictitious time index starting 1/1/1970 00:00 is automatically set. This is done because pypsa needs time indeces. To find out which time index corresponds to which case check out:
edisgo.timeseries.timeindex_worst_cases
Predefined
Use this mode if you want to set time series by component type. You may either provide your own time series or use ones provided through the OpenEnergy DataBase or other python tools. This mode can be invoked as follows:
edisgo.set_time_series_active_power_predefined()
For the following components you can use existing time series:
Fluctuating generators: Feed-in time series for solar and wind power plants can be retrieved from the OpenEnergy DataBase.
Conventional loads: Standard load profiles for the different sectors residential, commercial, agricultural and industrial are generated using the oemof demandlib.
For all other components you need to provide your own time series. Time series for
heat pumps cannot be set using this mode.
See set_time_series_active_power_predefined for more information.
When using this mode make sure to previously set the time index. This can either be done
upon initialisation of the EDisGo object by providing the input parameter ‘timeindex’ or
by using the function set_timeindex.
Optimised
Use this mode to optimise flexibilities, e.g. charging of electric vehicles or dispatch of heat pumps with thermal storage units.
Todo
Add more details once the optimisation is merged.
Heuristic
Use this mode to use heuristics to set time series. So far, only heuristics for electric vehicle charging are implemented. The charging strategies can be invoked as follows:
edisgo.apply_charging_strategy()
See function docstring of apply_charging_strategy() or
documentation section Charging strategies for more information.
Further, there is currently one operating strategy for heat pumps implemented where the heat demand is directly served by the heat pump without buffering heat using a thermal storage. The operating strategy can be invoked as follows:
edisgo.apply_heat_pump_operating_strategy()
See function docstring of apply_heat_pump_operating_strategy
for more information.
Reactive power time series
There are so far two options how to set reactive power time series:
“manual”: providing your own time series
“fixed
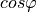 ”: using a fixed power factor
”: using a fixed power factor
It is perspectively planned to also provide reactive power controls Q(U) and
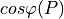 .
.
Manual
See active power Manual mode documentation.
Fixed
Use this mode to set reactive power time series using fixed power factors. It can be invoked as follows:
edisgo.set_time_series_reactive_power_control()
See set_time_series_reactive_power_control for more information.
When using this mode make sure to previously set active power time series.
Identifying grid issues
As detailed in A minimum working example, once you set up your scenario by instantiating an
EDisGo object, you are ready for a grid analysis and identifying grid
issues (line overloading and voltage issues) using analyze():
# Do non-linear power flow analysis for MV and LV grid
edisgo.analyze()
The analyze function conducts a non-linear power flow using PyPSA.
The range of time analyzed by the power flow analysis is by default defined by the
timeindex(), that can be given
as an input to the EDisGo object through the parameter timeindex or is
otherwise set automatically. If you want to change
the time steps that are analyzed, you can specify those through the parameter
timesteps of the analyze function.
Make sure that the specified time steps are a subset of
timeindex().
Grid expansion
Grid expansion can be invoked by reinforce():
# Reinforce grid due to overloading and overvoltage issues
edisgo.reinforce()
You can further specify e.g. if to conduct a combined analysis for MV and LV
(regarding allowed voltage deviations) or if to only calculate grid expansion
needs without changing the topology of the graph. See
reinforce_grid() for more information.
Costs for the grid expansion measures can be obtained as follows:
# Get costs of grid expansion
costs = edisgo.results.grid_expansion_costs
Further information on the grid reinforcement methodology can be found in section Grid expansion.
Electromobility
Electromobility data including charging processes as well as information on potential charging sites and
integrated charging parks are stored in the
Electromobility object.
You can access these data as follows:
# Access DataFrame with all SimBEV charging processes
edisgo.electromobility.charging_processes_df
# Access GeoDataFrame with all TracBEV potential charging parks
edisgo.electromobility.potential_charging_parks_gdf
# Access DataFrame with all charging parks that got integrated
edisgo.electromobility.integrated_charging_parks_df
The integrated charging points are also stored in the Topology
object and can be accessed as follows:
# Access DataFrame with all integrated charging points.
edisgo.topology.charging_points_df
So far, adding electromobility data to an eDisGo object requires electromobility data from SimBEV (required version: 3083c5a) and TracBEV (required version: 14d864c) to be stored in the directories specified through the parameters simbev_directory and tracbev_directory. SimBEV provides data on standing times, charging demand, etc. per vehicle, whereas TracBEV provides potential charging point locations.
Todo
Add information on how to retrieve SimBEV and TracBEV data
Here is a small example on how to import electromobility data and apply a charging strategy. A more extensive example can be found in the example jupyter notebook electromobility_example.
import pandas as pd
from edisgo import EDisGo
# Set up the EDisGo object
timeindex = pd.date_range("1/1/2011", periods=24*7, freq="H")
edisgo = EDisGo(
ding0_grid=dingo_grid_path,
timeindex=timeindex
)
edisgo.set_time_series_active_power_predefined(
fluctuating_generators_ts="oedb",
dispatchable_generators_ts=pd.DataFrame(
data=1, columns=["other"], index=timeindex),
conventional_loads_ts="demandlib",
)
edisgo.set_time_series_reactive_power_control()
# Resample edisgo timeseries to 15-minute resolution to match with SimBEV and
# TracBEV data
edisgo.resample_timeseries()
# Import electromobility data
edisgo.import_electromobility(
simbev_directory=simbev_path,
tracbev_directory=tracbev_path,
)
# Apply charging strategy
edisgo.apply_charging_strategy(strategy="dumb")
Further information on the electromobility integration methodology and the charging strategies can be found in section Electromobility integration.
Heat pumps
Heat pump data including the heat pump’s time variant COP, heat demand to be served
as well as thermal storage capacities are stored in the
HeatPump object.
You can access these data as follows:
# Access DataFrame with COP time series
edisgo.heat_pump.cop_df
# Access DataFrame with heat demand time series
edisgo.heat_pump.heat_demand_df
# Access DataFrame with information on thermal storage capacities
edisgo.heat_pump.thermal_storage_units_df
The heat pumps themselves are also stored in the Topology
object and can be accessed as follows:
# Access DataFrame with all integrated heat pumps
edisgo.topology.loads_df[edisgo.topology.loads_df.type == "heat_pump"]
Here is a small example on how to integrate a heat pump and apply an operating strategy.
import pandas as pd
from edisgo import EDisGo
# Set up the EDisGo object
timeindex = pd.date_range("1/1/2011", periods=4, freq="H")
edisgo = EDisGo(
ding0_grid=dingo_grid_path,
timeindex=timeindex
)
# Set up dummy heat pump data
bus = edisgo.topology.loads_df[
edisgo.topology.loads_df.sector == "residential"].bus[0]
heat_pump_params = {"bus": bus, "p_set": 0.015, "type": "heat_pump"}
cop = pd.Series([1.0, 2.0, 1.5, 3.4], index=timeindex)
heat_demand = pd.Series([0.01, 0.03, 0.015, 0.0], index=timeindex)
# Add heat pump to grid topology
hp_name = edisgo.add_component("load", **heat_pump_params)
# Add heat pump COP and heat demand to be served
edisgo.heat_pump.set_cop(edisgo, cop.to_frame(name=hp_name))
edisgo.heat_pump.set_heat_demand(edisgo, heat_demand.to_frame(name=hp_name))
# Apply operating strategy - this sets the heat pump's dispatch time series
# in timeseries.loads_active_power
edisgo.apply_heat_pump_operating_strategy()
hp_dispatch = edisgo.timeseries.loads_active_power.loc[:, hp_name]
hp_dispatch.plot()
Battery storage systems
Battery storage systems can be integrated into the grid as an alternative to classical grid expansion. Here are two small examples on how to integrate a storage unit manually. In the first one, the EDisGo object is set up for a worst-case analysis, wherefore no time series needs to be provided for the storage unit, as worst-case definition is used. In the second example, a time series analysis is conducted, wherefore a time series for the storage unit needs to be provided.
from edisgo import EDisGo
# Set up EDisGo object
edisgo = EDisGo(ding0_grid=dingo_grid_path)
# Get random bus to connect storage to
random_bus = edisgo.topology.buses_df.index[3]
# Add storage instance
edisgo.add_component(
comp_type="storage_unit",
add_ts=False,
bus=random_bus,
p_nom=4
)
# Set up worst case time series for loads, generators and storage unit
edisgo.set_time_series_worst_case_analysis()
import pandas as pd
from edisgo import EDisGo
# Set up the EDisGo object
timeindex = pd.date_range("1/1/2011", periods=4, freq="H")
edisgo = EDisGo(
ding0_grid=dingo_grid_path,
generator_scenario="ego100",
timeindex=timeindex
)
# Add time series for loads and generators
timeseries_generation_dispatchable = pd.DataFrame(
{"biomass": [1] * len(timeindex),
"coal": [1] * len(timeindex),
"other": [1] * len(timeindex)
},
index=timeindex
)
edisgo.set_time_series_active_power_predefined(
conventional_loads_ts="demandlib",
fluctuating_generators_ts="oedb",
dispatchable_generators_ts=timeseries_generation_dispatchable
)
edisgo.set_time_series_reactive_power_control()
# Add storage unit to random bus with time series
edisgo.add_component(
comp_type="storage_unit",
bus=edisgo.topology.buses_df.index[3],
p_nom=4,
ts_active_power=pd.Series(
[-3.4, 2.5, -3.4, 2.5],
index=edisgo.timeseries.timeindex),
ts_reactive_power=pd.Series(
[0., 0., 0., 0.],
index=edisgo.timeseries.timeindex)
)
To optimise storage positioning and operation eDisGo provides the options to use a heuristic (described in section Storage integration) or an optimal power flow approach. However, the storage integration heuristic is not yet adapted to the refactored code and therefore not available, and the OPF is not maintained and may therefore not work out of the box. Following you find an example on how to use the OPF to find the optimal storage positions in the grid with regard to grid expansion costs. Storage operation is optimized at the same time. The example uses the same EDisGo instance as above. A total storage capacity of 10 MW is distributed in the grid. storage_buses can be used to specify certain buses storage units may be connected to. This does not need to be provided but will speed up the optimization.
random_bus = edisgo.topology.buses_df.index[3:13]
edisgo.perform_mp_opf(
timesteps=period,
scenario="storage",
storage_units=True,
storage_buses=busnames,
total_storage_capacity=10.0,
results_path=results_path)
Curtailment
The curtailment function is used to spatially distribute the power that is to be curtailed. To optimise which generators should be curtailed eDisGo provides the options to use a heuristics (heuristics feedin-proportional and voltage-based, in detail explained in section Curtailment) or an optimal power flow approach. However, the heuristics are not yet adapted to the refactored code and therefore not available, and the OPF is not maintained and may therefore not work out of the box.
In the following example the optimal power flow is used to find the optimal generator curtailment with regard to minimizing grid expansion costs for given curtailment requirements. It uses the EDisGo object from above.
edisgo.perform_mp_opf(
timesteps=period,
scenario='curtailment',
results_path=results_path,
curtailment_requirement=True,
curtailment_requirement_series=[10, 20, 15, 0])
Plots
Todo
Add plotly plot option
EDisGo provides a bunch of predefined plots to e.g. plot the MV grid topology, line loading and node voltages in the MV grid or as a histograms.
# plot MV grid topology on a map
edisgo.plot_mv_grid_topology()
# plot grid expansion costs for lines in the MV grid and stations on a map
edisgo.plot_mv_grid_expansion_costs()
# plot voltage histogram
edisgo.histogram_voltage()
See EDisGo class for more plots and plotting options.
Results
Results such as voltages at nodes and line loading from the power flow analysis as well as
grid expansion costs are provided through the Results class
and can be accessed the following way:
edisgo.results
Get voltages at nodes from v_res
and line loading from s_res or
i_res.
equipment_changes holds details about measures
performed during grid expansion. Associated costs can be obtained through
grid_expansion_costs.
Flexibility measures may not entirely resolve all issues.
These unresolved issues are listed in unresolved_issues.
Results can be saved to csv files with:
edisgo.results.save('path/to/results/directory/')
See save() for more information.