edisgo.edisgo¶
Module Contents¶
Classes¶
Provides the top-level API for invocation of data import, power flow |
Functions¶
|
Restores EDisGo object from pickle file. |
|
Sets up EDisGo object from csv files. |
- class edisgo.edisgo.EDisGo(**kwargs)[source]¶
Provides the top-level API for invocation of data import, power flow analysis, network reinforcement, flexibility measures, etc..
- Parameters:
ding0_grid (
str) – Path to directory containing csv files of network to be loaded.generator_scenario (None or
str, optional) – If None, the generator park of the imported grid is kept as is. Otherwise defines which scenario of future generator park to use and invokes grid integration of these generators. Possible options are ‘nep2035’ and ‘ego100’. These are scenarios from the research project open_eGo (see final report for more information on the scenarios). Seeimport_generatorsfor further information on how generators are integrated and what further options there are. Default: None.timeindex (None or pandas.DatetimeIndex, optional) – Defines the time steps feed-in and demand time series of all generators, loads and storage units need to be set. The time index is for example used as default for time steps considered in the power flow analysis and when checking the integrity of the network. Providing a time index is only optional in case a worst case analysis is set up using
set_time_series_worst_case_analysis(). In all other cases a time index needs to be set manually.config_path (None or str or dict) –
Path to the config directory. Options are:
- ’default’ (default)
If config_path is set to ‘default’, the provided default config files are used directly.
- str
If config_path is a string, configs will be loaded from the directory specified by config_path. If the directory does not exist, it is created. If config files don’t exist, the default config files are copied into the directory.
- dict
A dictionary can be used to specify different paths to the different config files. The dictionary must have the following keys:
’config_db_tables’
’config_grid’
’config_grid_expansion’
’config_timeseries’
Values of the dictionary are paths to the corresponding config file. In contrast to the other options, the directories and config files must exist and are not automatically created.
- None
If config_path is None, configs are loaded from the edisgo default config directory ($HOME$/.edisgo). If the directory does not exist, it is created. If config files don’t exist, the default config files are copied into the directory.
Default: “default”.
legacy_ding0_grids (bool) – Allow import of old ding0 grids. Default: True.
- topology¶
The topology is a container object holding the topology of the grids including buses, lines, transformers, switches and components connected to the grid including generators, loads and storage units.
- Type:
- timeseries¶
Container for active and reactive power time series of generators, loads and storage units.
- Type:
- results¶
This is a container holding all calculation results from power flow analyses and grid reinforcement.
- Type:
- electromobility¶
This class holds data on charging processes (how long cars are parking at a charging station, how much they need to charge, etc.) necessary to apply different charging strategies, as well as information on potential charging sites and integrated charging parks.
- Type:
- heat_pump¶
This is a container holding heat pump data such as COP, heat demand to be served and heat storage information.
- Type:
- overlying_grid¶
This is a container holding data from the overlying grid such as curtailment requirements or power plant dispatch.
- Type:
- property config¶
eDisGo configuration data.
- import_ding0_grid(path, legacy_ding0_grids=True)[source]¶
Import ding0 topology data from csv files in the format as Ding0 provides it.
- set_timeindex(timeindex)[source]¶
Sets
timeindexall time-dependent attributes are indexed by.The time index is for example used as default for time steps considered in the power flow analysis and when checking the integrity of the network.
- Parameters:
timeindex (pandas.DatetimeIndex) – Time index to set.
- set_time_series_manual(generators_p=None, loads_p=None, storage_units_p=None, generators_q=None, loads_q=None, storage_units_q=None)[source]¶
Sets given component time series.
If time series for a component were already set before, they are overwritten.
- Parameters:
generators_p (pandas.DataFrame) – Active power time series in MW of generators. Index of the data frame is a datetime index. Columns contain generators names of generators to set time series for. Default: None.
loads_p (pandas.DataFrame) – Active power time series in MW of loads. Index of the data frame is a datetime index. Columns contain load names of loads to set time series for. Default: None.
storage_units_p (pandas.DataFrame) – Active power time series in MW of storage units. Index of the data frame is a datetime index. Columns contain storage unit names of storage units to set time series for. Default: None.
generators_q (pandas.DataFrame) – Reactive power time series in MVA of generators. Index of the data frame is a datetime index. Columns contain generators names of generators to set time series for. Default: None.
loads_q (pandas.DataFrame) – Reactive power time series in MVA of loads. Index of the data frame is a datetime index. Columns contain load names of loads to set time series for. Default: None.
storage_units_q (pandas.DataFrame) – Reactive power time series in MVA of storage units. Index of the data frame is a datetime index. Columns contain storage unit names of storage units to set time series for. Default: None.
Notes
This function raises a warning in case a time index was not previously set. You can set the time index upon initialisation of the EDisGo object by providing the input parameter ‘timeindex’ or using the function
set_timeindex. Also make sure that the time steps for which time series are provided include the set time index.
- set_time_series_worst_case_analysis(cases=None, generators_names=None, loads_names=None, storage_units_names=None)[source]¶
Sets demand and feed-in of all loads, generators and storage units for the specified worst cases.
See
set_worst_casefor more information.- Parameters:
cases (str or list(str)) – List with worst-cases to generate time series for. Can be ‘feed-in_case’, ‘load_case’ or both. Defaults to None in which case both ‘feed-in_case’ and ‘load_case’ are set up.
generators_names (list(str)) – Defines for which generators to set worst case time series. If None, time series are set for all generators. Default: None.
loads_names (list(str)) – Defines for which loads to set worst case time series. If None, time series are set for all loads. Default: None.
storage_units_names (list(str)) – Defines for which storage units to set worst case time series. If None, time series are set for all storage units. Default: None.
- set_time_series_active_power_predefined(fluctuating_generators_ts=None, fluctuating_generators_names=None, dispatchable_generators_ts=None, dispatchable_generators_names=None, conventional_loads_ts=None, conventional_loads_names=None, charging_points_ts=None, charging_points_names=None, **kwargs)[source]¶
Uses predefined feed-in or demand profiles to set active power time series.
Predefined profiles comprise i.e. standard electric conventional load profiles for different sectors generated using the oemof demandlib or feed-in time series of fluctuating solar and wind generators provided on the OpenEnergy DataBase. This function can also be used to provide your own profiles per technology or load sector.
The active power time series are written to
generators_active_powerorloads_active_power. As data inTimeSeriesis indexed bytimeindexit is better to settimeindexbefore calling this function. You can set the time index upon initialisation of the EDisGo object by providing the input parameter ‘timeindex’ or using the functionset_timeindex. Also make sure that the time steps of self-provided time series include the set time index.- Parameters:
fluctuating_generators_ts (str or pandas.DataFrame or None) –
Defines option to set technology-specific or technology- and weather cell specific active power time series of wind and solar generators. Possible options are:
’oedb’
Technology- and weather cell-specific hourly feed-in time series are obtained from the OpenEnergy DataBase. See
edisgo.io.timeseries_import.feedin_oedb()for more information.This option requires that the parameter engine is provided in case new ding0 grids with geo-referenced LV grids are used. For further settings, the parameter timeindex can also be provided.
-
DataFrame with self-provided feed-in time series per technology or per technology and weather cell ID normalized to a nominal capacity of 1. In case time series are provided only by technology, columns of the DataFrame contain the technology type as string. In case time series are provided by technology and weather cell ID columns need to be a pandas.MultiIndex with the first level containing the technology as string and the second level the weather cell ID as integer. Index needs to be a pandas.DatetimeIndex.
When importing a ding0 grid and/or using predefined scenarios of the future generator park, each generator has an assigned weather cell ID that identifies the weather data cell from the weather data set used in the research project open_eGo to determine feed-in profiles. The weather cell ID can be retrieved from column weather_cell_id in
generators_dfand could be overwritten to use own weather cells. None
If None, time series are not set.
Default: None.
fluctuating_generators_names (list(str) or None) – Defines for which fluctuating generators to apply technology-specific time series. See parameter generator_names in
predefined_fluctuating_generators_by_technologyfor more information. Default: None.dispatchable_generators_ts (pandas.DataFrame or None) – Defines which technology-specific time series to use to set active power time series of dispatchable generators. See parameter ts_generators in
predefined_dispatchable_generators_by_technologyfor more information. If None, no time series of dispatchable generators are set. Default: None.dispatchable_generators_names (list(str) or None) – Defines for which dispatchable generators to apply technology-specific time series. See parameter generator_names in
predefined_dispatchable_generators_by_technologyfor more information. Default: None.conventional_loads_ts (str or pandas.DataFrame or None) –
Defines option to set active power time series of conventional loads. Possible options are:
’oedb’
Sets active power demand time series using individual hourly electricity load time series for one year obtained from the OpenEnergy DataBase.
This option requires that the parameters engine and scenario are provided. For further settings, the parameter timeindex can also be provided.
’demandlib’
Sets active power demand time series using hourly electricity load time series obtained using standard electric load profiles from the oemof demandlib. The demandlib provides sector-specific time series for the sectors ‘residential’, ‘cts’, ‘industrial’, and ‘agricultural’.
For further settings, the parameter timeindex can also be provided.
-
Sets active power demand time series using sector-specific demand time series provided in this DataFrame. The load time series per sector need to be normalized to an annual consumption of 1. Index needs to be a pandas.DatetimeIndex. Columns need to contain the sector as string. In the current grid existing load types can be retrieved from column sector in
loads_df(make sure to select type ‘conventional_load’). In ding0 grids the differentiated sectors are ‘residential’, ‘cts’, and ‘industrial’. None
If None, conventional load time series are not set.
Default: None.
conventional_loads_names (list(str) or None) – Defines for which conventional loads to set time series. In case conventional_loads_ts is ‘oedb’ see parameter load_names in
edisgo.io.timeseries_import.electricity_demand_oedb()for more information. For other cases see parameter load_names inpredefined_conventional_loads_by_sectorfor more information. Default: None.charging_points_ts (pandas.DataFrame or None) – Defines which use-case-specific time series to use to set active power time series of charging points. See parameter ts_loads in
predefined_charging_points_by_use_casefor more information. If None, no time series of charging points are set. Default: None.charging_points_names (list(str) or None) – Defines for which charging points to apply use-case-specific time series. See parameter load_names in
predefined_charging_points_by_use_casefor more information. Default: None.engine (sqlalchemy.Engine) – Database engine. This parameter is only required in case conventional_loads_ts or fluctuating_generators_ts is ‘oedb’.
scenario (str) – Scenario for which to retrieve demand data. Possible options are ‘eGon2035’ and ‘eGon100RE’. This parameter is only required in case conventional_loads_ts is ‘oedb’.
timeindex (pandas.DatetimeIndex or None) – This parameter can optionally be provided in case conventional_loads_ts is ‘oedb’ or ‘demandlib’ and in case fluctuating_generators_ts is ‘oedb’. It is used to specify time steps for which to set active power data. Leap years can currently not be handled when data is retrieved from the oedb. In case the given timeindex contains a leap year, the data will be indexed using a default year and set for the whole year. If no timeindex is provided, the timeindex set in
timeindexis used. Iftimeindexis not set, the data is indexed using a default year and set for the whole year.
- set_time_series_reactive_power_control(control='fixed_cosphi', generators_parametrisation='default', loads_parametrisation='default', storage_units_parametrisation='default')[source]¶
Set reactive power time series of components.
- Parameters:
control (str) – Type of reactive power control to apply. Currently, the only option is ‘fixed_coshpi’. See
fixed_cosphifor further information.generators_parametrisation (str or pandas.DataFrame) – See parameter generators_parametrisation in
fixed_cosphifor further information. Here, per default, the option ‘default’ is used.loads_parametrisation (str or pandas.DataFrame) – See parameter loads_parametrisation in
fixed_cosphifor further information. Here, per default, the option ‘default’ is used.storage_units_parametrisation (str or pandas.DataFrame) – See parameter storage_units_parametrisation in
fixed_cosphifor further information. Here, per default, the option ‘default’ is used.
Notes
Be careful to set parametrisation of other component types to None if you only want to set reactive power of certain components. See example below for further information.
Examples
To only set reactive power time series of one generator using default configurations you can do the following:
>>> self.set_time_series_reactive_power_control( >>> generators_parametrisation=pd.DataFrame( >>> { >>> "components": [["Generator_1"]], >>> "mode": ["default"], >>> "power_factor": ["default"], >>> }, >>> index=[1], >>> ), >>> loads_parametrisation=None, >>> storage_units_parametrisation=None >>> )
In the example above, loads_parametrisation and storage_units_parametrisation need to be set to None, otherwise already existing time series would be overwritten.
To only change configuration of one load and for all other components use default configurations you can do the following:
>>> self.set_time_series_reactive_power_control( >>> loads_parametrisation=pd.DataFrame( >>> { >>> "components": [["Load_1"], >>> self.topology.loads_df.index.drop(["Load_1"])], >>> "mode": ["capacitive", "default"], >>> "power_factor": [0.98, "default"], >>> }, >>> index=[1, 2], >>> ) >>> )
In the example above, generators_parametrisation and storage_units_parametrisation do not need to be set as default configurations are per default used for all generators and storage units anyway.
- to_pypsa(mode=None, timesteps=None, check_edisgo_integrity=False, **kwargs)[source]¶
Convert grid to PyPSA.Network representation.
You can choose between translation of the MV and all underlying LV grids (mode=None (default)), the MV network only (mode=’mv’ or mode=’mvlv’) or a single LV network (mode=’lv’).
- Parameters:
mode (str) –
Determines network levels that are translated to PyPSA.Network. Possible options are:
None
MV and underlying LV networks are exported. This is the default.
’mv’
Only MV network is exported. MV/LV transformers are not exported in this mode. Loads, generators and storage units in underlying LV grids are connected to the respective MV/LV station’s primary side. Per default, they are all connected separately, but you can also choose to aggregate them. See parameters aggregate_loads, aggregate_generators and aggregate_storages for more information.
’mvlv’
This mode works similar as mode ‘mv’, with the difference that MV/LV transformers are as well exported and LV components connected to the respective MV/LV station’s secondary side. Per default, all components are connected separately, but you can also choose to aggregate them. See parameters aggregate_loads, aggregate_generators and aggregate_storages for more information.
’lv’
Single LV network topology including the MV/LV transformer is exported. The LV grid to export is specified through the parameter lv_grid_id. The slack is positioned at the secondary side of the MV/LV station.
timesteps (pandas.DatetimeIndex or pandas.Timestamp) – Specifies which time steps to export to pypsa representation to e.g. later on use in power flow analysis. It defaults to None in which case all time steps in
timeindexare used. Default: None.check_edisgo_integrity (bool) – Check integrity of edisgo object before translating to pypsa. This option is meant to help the identification of possible sources of errors if the power flow calculations fail. See
check_integrityfor more information. Default: False.use_seed (bool) – Use a seed for the initial guess for the Newton-Raphson algorithm. Only available when MV level is included in the power flow analysis. If True, uses voltage magnitude results of previous power flow analyses as initial guess in case of PQ buses. PV buses currently do not occur and are therefore currently not supported. Default: False.
lv_grid_id (int or str) – ID (e.g. 1) or name (string representation, e.g. “LVGrid_1”) of LV grid to export in case mode is ‘lv’. Default: None.
aggregate_loads (str) – Mode for load aggregation in LV grids in case mode is ‘mv’ or ‘mvlv’. Can be ‘sectoral’ aggregating the loads sector-wise, ‘all’ aggregating all loads into one or None, not aggregating loads but appending them to the station one by one. Default: None.
aggregate_generators (str) – Mode for generator aggregation in LV grids in case mode is ‘mv’ or ‘mvlv’. Can be ‘type’ aggregating generators per generator type, ‘curtailable’ aggregating ‘solar’ and ‘wind’ generators into one and all other generators into another one, or None, where no aggregation is undertaken and generators are added to the station one by one. Default: None.
aggregate_storages (str) – Mode for storage unit aggregation in LV grids in case mode is ‘mv’ or ‘mvlv’. Can be ‘all’ where all storage units in an LV grid are aggregated to one storage unit or None, in which case no aggregation is conducted and storage units are added to the station. Default: None.
- Returns:
PyPSA.Network representation.
- Return type:
- to_powermodels(s_base=1, flexible_cps=None, flexible_hps=None, flexible_loads=None, flexible_storage_units=None, opf_version=1)[source]¶
Convert eDisGo representation of the network topology and timeseries to PowerModels network data format.
- Parameters:
s_base (int) – Base value of apparent power for per unit system. Default: 1 MVA
flexible_cps (numpy.ndarray or None) – Array containing all charging points that allow for flexible charging.
flexible_hps (numpy.ndarray or None) – Array containing all heat pumps that allow for flexible operation due to an attached heat storage.
flexible_loads (numpy.ndarray or None) – Array containing all flexible loads that allow for application of demand side management strategy.
flexible_storage_units (numpy.ndarray or None) – Array containing all flexible storages. Non-flexible storages operate to optimize self consumption. Default: None.
opf_version (int) – Version of optimization models to choose from. Must be one of [1, 2, 3, 4]. For more information see
edisgo.opf.powermodels_opf.pm_optimize(). Default: 1.
- Returns:
Dictionary that contains all network data in PowerModels network data format.
- Return type:
- pm_optimize(s_base=1, flexible_cps=None, flexible_hps=None, flexible_loads=None, flexible_storage_units=None, opf_version=1, method='soc', warm_start=False, silence_moi=False, save_heat_storage=True, save_slack_gen=True, save_slacks=True)[source]¶
Run OPF in julia subprocess and write results of OPF back to edisgo object.
Results of OPF are time series of operation schedules of flexibilities.
- Parameters:
s_base (int) – Base value of apparent power for per unit system. Default: 1 MVA.
flexible_cps (numpy.ndarray or None) – Array containing all charging points that allow for flexible charging. Default: None.
flexible_hps (numpy.ndarray or None) – Array containing all heat pumps that allow for flexible operation due to an attached heat storage. Default: None.
flexible_loads (numpy.ndarray or None) – Array containing all flexible loads that allow for application of demand side management strategy. Default: None.
flexible_storage_units (numpy.ndarray or None) – Array containing all flexible storages. Non-flexible storages operate to optimize self consumption. Default: None.
opf_version (int) – Version of optimization models to choose from. Must be one of [1, 2, 3, 4]. For more information see
edisgo.opf.powermodels_opf.pm_optimize(). Default: 1.method (str) – Optimization method to use. Must be either “soc” (Second Order Cone) or “nc” (Non Convex). For more information see
edisgo.opf.powermodels_opf.pm_optimize(). Default: “soc”.warm_start (bool) – If set to True and if method is set to “soc”, non-convex IPOPT OPF will be run additionally and will be warm started with Gurobi SOC solution. Warm-start will only be run if results for Gurobi’s SOC relaxation is exact. Default: False.
silence_moi (bool) – If set to True, MathOptInterface’s optimizer attribute “MOI.Silent” is set to True in julia subprocess. This attribute is for silencing the output of an optimizer. When set to True, it requires the solver to produce no output, hence there will be no logging coming from julia subprocess in python process. Default: False.
- to_graph()[source]¶
Returns networkx graph representation of the grid.
- Returns:
Graph representation of the grid as networkx Ordered Graph, where lines are represented by edges in the graph, and buses and transformers are represented by nodes.
- Return type:
- import_generators(generator_scenario=None, **kwargs)[source]¶
Gets generator park for specified scenario and integrates generators into grid.
The generator data is retrieved from the open energy platform. Decommissioned generators are removed from the grid, generators with changed capacity updated and new generators newly integrated into the grid.
In case you are using new ding0 grids, where the LV is geo-referenced, the supported data source is scenario data generated in the research project eGo^n. You can choose between two scenarios: ‘eGon2035’ and ‘eGon100RE’. For more information on database tables used and how generator park is adapted see
oedb().In case you are using old ding0 grids, where the LV is not geo-referenced, the supported data source is scenario data generated in the research project open_eGo. You can choose between two scenarios: ‘nep2035’ and ‘ego100’. You can get more information on the scenarios in the final report. For more information on database tables used and how generator park is adapted see
oedb_legacy().After the generator park is adapted there may be grid issues due to the additional feed-in. These are not solved automatically. If you want to have a stable grid without grid issues you can invoke the automatic grid expansion through the function
reinforce.- Parameters:
generator_scenario (str) – Scenario for which to retrieve generator data. In case you are using new ding0 grids, where the LV is geo-referenced, possible options are ‘eGon2035’ and ‘eGon100RE’. In case you are using old ding0 grids, where the LV is not geo-referenced, possible options are ‘nep2035’ and ‘ego100’.
kwargs – In case you are using new ding0 grids, where the LV is geo-referenced, a database engine needs to be provided through keyword argument engine. In case you are using old ding0 grids, where the LV is not geo-referenced, you can check
edisgo.io.generators_import.oedb_legacy()for possible keyword arguments.
- analyze(mode: str | None = None, timesteps: pandas.Timestamp | pandas.DatetimeIndex | None = None, raise_not_converged: bool = True, troubleshooting_mode: str | None = None, range_start: numbers.Number = 0.1, range_num: int = 10, scale_timeseries: float | None = None, **kwargs) tuple[pandas.DatetimeIndex, pandas.DatetimeIndex][source]¶
Conducts a static, non-linear power flow analysis.
Conducts a static, non-linear power flow analysis using PyPSA and writes results (active, reactive and apparent power as well as current on lines and voltages at buses) to
Results(e.g.v_resfor voltages).- Parameters:
mode (str or None) –
Allows to toggle between power flow analysis for the whole network or just the MV or one LV grid. Possible options are:
None (default)
Power flow analysis is conducted for the whole network including MV grid and underlying LV grids.
’mv’
Power flow analysis is conducted for the MV level only. LV loads, generators and storage units are aggregated at the respective MV/LV stations’ primary side. Per default, they are all connected separately, but you can also choose to aggregate them. See parameters aggregate_loads, aggregate_generators and aggregate_storages in
to_pypsafor more information.’mvlv’
Power flow analysis is conducted for the MV level only. In contrast to mode ‘mv’ LV loads, generators and storage units are in this case aggregated at the respective MV/LV stations’ secondary side. Per default, they are all connected separately, but you can also choose to aggregate them. See parameters aggregate_loads, aggregate_generators and aggregate_storages in
to_pypsafor more information.’lv’
Power flow analysis is conducted for one LV grid only. ID or name of the LV grid to conduct power flow analysis for needs to be provided through keyword argument ‘lv_grid_id’ as integer or string. See parameter lv_grid_id in
to_pypsafor more information. The slack is positioned at the secondary side of the MV/LV station.
timesteps (pandas.DatetimeIndex or pandas.Timestamp) – Timesteps specifies for which time steps to conduct the power flow analysis. It defaults to None in which case all time steps in
timeindexare used.raise_not_converged (bool) – If True, an error is raised in case power flow analysis did not converge for all time steps. Default: True.
troubleshooting_mode (str or None) –
Two optional troubleshooting methods in case of non-convergence of nonlinear power flow (cf. [1])
- None (default)
Power flow analysis is conducted using nonlinear power flow method.
- ’lpf’
Non-linear power flow initial guess is seeded with the voltage angles from the linear power flow.
- ’iteration’
Power flow analysis is conducted by reducing all power values of generators and loads to a fraction, e.g. 10%, solving the load flow and using it as a seed for the power at 20%, iteratively up to 100%. Using parameters range_start and range_num you can define at what scaling factor the iteration should start and how many iterations should be conducted.
range_start (float, optional) – Specifies the minimum fraction that power values are set to when using troubleshooting_mode ‘iteration’. Must be between 0 and 1. Default: 0.1.
range_num (int, optional) – Specifies the number of fraction samples to generate when using troubleshooting_mode ‘iteration’. Must be non-negative. Default: 10.
scale_timeseries (float or None, optional) – If a value is given, the timeseries in the pypsa object are scaled with this factor (values between 0 and 1 will scale down the time series and values above 1 will scale the timeseries up). Downscaling of time series can be used to check if power flow converges for smaller grid loads. If None, timeseries are not scaled. In case of troubleshooting_mode ‘iteration’ this parameter is ignored. Default: None.
kwargs (dict) – Possible other parameters comprise all other parameters that can be set in
edisgo.io.pypsa_io.to_pypsa().
- Returns:
First index contains time steps for which power flow analysis did converge. Second index contains time steps for which power flow analysis did not converge.
- Return type:
References
[1] https://pypsa.readthedocs.io/en/latest/troubleshooting.html
- reinforce(timesteps_pfa: str | pandas.DatetimeIndex | pandas.Timestamp | None = None, reduced_analysis: bool = False, copy_grid: bool = False, max_while_iterations: int = 20, split_voltage_band: bool = True, mode: str | None = None, without_generator_import: bool = False, n_minus_one: bool = False, catch_convergence_problems: bool = False, **kwargs) edisgo.network.results.Results[source]¶
Reinforces the network and calculates network expansion costs.
If the
edisgo.network.timeseries.TimeSeries.is_worst_caseis True input for timesteps_pfa is overwritten and therefore ignored.See Features in detail for more information on how network reinforcement is conducted.
- Parameters:
timesteps_pfa (str or pandas.DatetimeIndex or pandas.Timestamp) –
timesteps_pfa specifies for which time steps power flow analysis is conducted and therefore which time steps to consider when checking for over-loading and over-voltage issues. It defaults to None in which case all timesteps in
timeindexare used. Possible options are:None Time steps in
timeindexare used.’snapshot_analysis’ Reinforcement is conducted for two worst-case snapshots. See
edisgo.tools.tools.select_worstcase_snapshots()for further explanation on how worst-case snapshots are chosen. Note: If you have large time series, choosing this option will save calculation time since power flow analysis is only conducted for two time steps. If your time series already represents the worst-case, keep the default value of None because finding the worst-case snapshots takes some time.pandas.DatetimeIndex or pandas.Timestamp Use this option to explicitly choose which time steps to consider.
reduced_analysis (bool) – If True, reinforcement is conducted for all time steps at which at least one branch shows its highest overloading or one bus shows its highest voltage violation. Time steps to consider are specified through parameter timesteps_pfa. If False, all time steps in parameter timesteps_pfa are used. Default: False.
copy_grid (bool) – If True, reinforcement is conducted on a copied grid and discarded. Default: False.
max_while_iterations (int) – Maximum number of times each while loop is conducted. Default: 20.
split_voltage_band (bool) – If True the allowed voltage band of +/-10 percent is allocated to the different voltage levels MV, MV/LV and LV according to config values set in section grid_expansion_allowed_voltage_deviations. If False, the same voltage limits are used for all voltage levels. Be aware that this does currently not work correctly. Default: True.
mode (str) –
Determines network levels reinforcement is conducted for. Specify
None to reinforce MV and LV network levels. None is the default.
’mv’ to reinforce MV level only, neglecting MV/LV stations, and LV network topology. LV load and generation is aggregated per LV network and directly connected to the primary side of the respective MV/LV station.
’mvlv’ to reinforce MV network level only, including MV/LV stations, and neglecting LV network topology. LV load and generation is aggregated per LV network and directly connected to the secondary side of the respective MV/LV station.
’lv’ to reinforce LV networks. In case an LV grid is specified through parameter lv_grid_id, the grid’s MV/LV station is not included. In case no LV grid ID is given, all MV/LV stations are included.
without_generator_import (bool) – If True, excludes lines that were added in the generator import to connect new generators from calculation of network expansion costs. Default: False.
n_minus_one (bool) – Determines whether n-1 security should be checked. Currently, n-1 security cannot be handled correctly, wherefore the case where this parameter is set to True will lead to an error being raised. Default: False.
catch_convergence_problems (bool) – Uses reinforcement strategy to reinforce not converging grid. Reinforces first with only converging timesteps. Reinforce again with at start not converging timesteps. If still not converging, scale timeseries. Default: False
is_worst_case (bool) – Is used to overwrite the return value from
edisgo.network.timeseries.TimeSeries.is_worst_case. If True, reinforcement is calculated for worst-case MV and LV cases separately.lv_grid_id (str or int or None) – LV grid id to specify the grid to check, if mode is “lv”. If no grid is specified, all LV grids are checked. In that case, the power flow analysis is conducted including the MV grid, in order to check loading and voltage drop/rise of MV/LV stations.
skip_mv_reinforcement (bool) – If True, MV is not reinforced, even if mode is “mv”, “mvlv” or None. This is used in case worst-case grid reinforcement is conducted in order to reinforce MV/LV stations for LV worst-cases. Default: False.
num_steps_loading (int) – In case reduced_analysis is set to True, this parameter can be used to specify the number of most critical overloading events to consider. If None, percentage is used. Default: None.
num_steps_voltage (int) – In case reduced_analysis is set to True, this parameter can be used to specify the number of most critical voltage issues to select. If None, percentage is used. Default: None.
percentage (float) – In case reduced_analysis is set to True, this parameter can be used to specify the percentage of most critical time steps to select. The default is 1.0, in which case all most critical time steps are selected. Default: 1.0.
use_troubleshooting_mode (bool) – In case reduced_analysis is set to True, this parameter can be used to specify how to handle non-convergence issues when determining the most critical time steps. If set to True, non-convergence issues are tried to be circumvented by reducing load and feed-in until the power flow converges. The most critical time steps are then determined based on the power flow results with the reduced load and feed-in. If False, an error will be raised in case time steps do not converge. Setting this to True doesn’t make sense for the grid reinforcement as the troubleshooting mode is only used when determining the most critical time steps not when running a power flow analysis to determine grid reinforcement needs. To handle non-convergence in the grid reinforcement set parameter catch_convergence_problems to True. Default: False.
run_initial_analyze (bool) – In case reduced_analysis is set to True, this parameter can be used to specify whether to run an initial analyze to determine most critical time steps or to use existing results. If set to False, use_troubleshooting_mode is ignored. Default: True.
weight_by_costs (bool) – In case reduced_analysis is set to True, this parameter can be used to specify whether to weight time steps by estimated grid expansion costs. See parameter weight_by_costs in
get_most_critical_time_steps()for more information. Default: False.
- Returns:
Returns the Results object holding network expansion costs, equipment changes, etc.
- Return type:
- add_component(comp_type, ts_active_power=None, ts_reactive_power=None, **kwargs)[source]¶
Adds single component to network.
Components can be lines or buses as well as generators, loads, or storage units. If add_ts is set to True, time series of elements are set as well. Currently, time series need to be provided.
- Parameters:
comp_type (str) – Type of added component. Can be ‘bus’, ‘line’, ‘load’, ‘generator’, or ‘storage_unit’.
ts_active_power (pandas.Series or None) – Active power time series of added component. Index of the series must contain all time steps in
timeindex. Values are active power per time step in MW. Defaults to None in which case no time series is set.ts_reactive_power (pandas.Series or str or None) –
Possible options are:
-
Reactive power time series of added component. Index of the series must contain all time steps in
timeindex. Values are reactive power per time step in MVA. ”default”
Reactive power time series is determined based on assumptions on fixed power factor of the component. To this end, the power factors set in the config section reactive_power_factor and the power factor mode, defining whether components behave inductive or capacitive, given in the config section reactive_power_mode, are used. This option requires you to provide an active power time series. In case it was not provided, reactive power cannot be set and a warning is raised.
None
No reactive power time series is set.
Default: None
-
**kwargs (dict) –
Attributes of added component. See respective functions for required entries.
’bus’ :
add_bus’line’ :
add_line’load’ :
add_load’generator’ :
add_generator’storage_unit’ :
add_storage_unit
- Returns:
The identifier of the newly integrated component as in index of
generators_df,loads_df, etc., depending on component type.- Return type:
- integrate_component_based_on_geolocation(comp_type, geolocation, voltage_level=None, add_ts=True, ts_active_power=None, ts_reactive_power=None, **kwargs)[source]¶
Adds single component to topology based on geolocation.
Currently, components can be generators, charging points, heat pumps and storage units.
See
connect_to_mv,connect_to_lvandconnect_to_lv_based_on_geolocationfor more information.- Parameters:
comp_type (str) – Type of added component. Can be ‘generator’, ‘charging_point’, ‘heat_pump’ or ‘storage_unit’.
geolocation (shapely.Point or tuple) – Geolocation of the new component. In case of tuple, the geolocation must be given in the form (longitude, latitude).
voltage_level (int, optional) – Specifies the voltage level the new component is integrated in. Possible options are 4 (MV busbar), 5 (MV grid), 6 (LV busbar) or 7 (LV grid). If no voltage level is provided the voltage level is determined based on the nominal power p_nom or p_set (given as kwarg). For this, upper limits up to which capacity a component is integrated into a certain voltage level (set in the config section grid_connection through the parameters ‘upper_limit_voltage_level_{4:7}’) are used.
add_ts (bool, optional) – Indicator if time series for component are added as well. Default: True.
ts_active_power (pandas.Series, optional) – Active power time series of added component. Index of the series must contain all time steps in
timeindex. Values are active power per time step in MW. If you want to add time series (if add_ts is True), you must provide a time series. It is not automatically retrieved.ts_reactive_power (pandas.Series, optional) – Reactive power time series of added component. Index of the series must contain all time steps in
timeindex. Values are reactive power per time step in MVA. If you want to add time series (if add_ts is True), you must provide a time series. It is not automatically retrieved.kwargs – Attributes of added component. See
add_generator,add_storage_unitrespectivelyadd_loadmethods for more information on required and optional parameters.
- Returns:
The identifier of the newly integrated component as in index of
generators_df,loads_dforstorage_units_df, depending on component type.- Return type:
- remove_component(comp_type, comp_name, drop_ts=True)[source]¶
Removes single component from network.
Components can be lines or buses as well as generators, loads, or storage units. If drop_ts is set to True, time series of elements are deleted as well.
- aggregate_components(aggregate_generators_by_cols=None, aggregate_loads_by_cols=None)[source]¶
Aggregates generators and loads at the same bus.
By default all generators respectively loads at the same bus are aggregated. You can specify further columns to consider in the aggregation, such as the generator type or the load sector. Make sure to always include the bus in the list of columns to aggregate by, as otherwise the topology would change.
Be aware that by aggregating components you loose some information e.g. on load sector or charging point use case.
- Parameters:
aggregate_generators_by_cols (list(str) or None) – List of columns to aggregate generators at the same bus by. Valid columns are all columns in
generators_df. If an empty list is given, generators are not aggregated. Defaults to None, in which case all generators at the same bus are aggregated.aggregate_loads_by_cols (list(str)) – List of columns to aggregate loads at the same bus by. Valid columns are all columns in
loads_df. If an empty list is given, generators are not aggregated. Defaults to None, in which case all loads at the same bus are aggregated.
- import_electromobility(data_source: str, scenario: str = None, engine: sqlalchemy.engine.base.Engine = None, charging_processes_dir: pathlib.PurePath | str = None, potential_charging_points_dir: pathlib.PurePath | str = None, import_electromobility_data_kwds=None, allocate_charging_demand_kwds=None)[source]¶
Imports electromobility data and integrates charging points into grid.
Electromobility data can be obtained from the OpenEnergy DataBase or from self-provided data. In case you want to use self-provided data, it needs to be generated using the tools SimBEV (required version: 3083c5a) and TracBEV (required version: 14d864c). SimBEV provides data on standing times, charging demand, etc. per vehicle, whereas TracBEV provides potential charging point locations.
After electromobility data is loaded, the charging demand from is allocated to potential charging points. Afterwards, all potential charging points with charging demand allocated to them are integrated into the grid.
Be aware that this function does not yield charging time series per charging point but only charging processes (see
charging_processes_dffor more information). The actual charging time series are determined through applying a charging strategy using the functioncharging_strategy.- Parameters:
data_source (str) –
Specifies source from where to obtain electromobility data. Possible options are:
”oedb”
Electromobility data is obtained from the OpenEnergy DataBase.
This option requires that the parameters scenario and engine are provided.
”directory”
Electromobility data is obtained from directories specified through parameters charging_processes_dir and potential_charging_points_dir.
scenario (str) – Scenario for which to retrieve electromobility data in case data_source is set to “oedb”. Possible options are “eGon2035” and “eGon100RE”.
engine (sqlalchemy.Engine) – Database engine. Needs to be provided in case data_source is set to “oedb”.
charging_processes_dir (str or pathlib.PurePath) – Directory holding data on charging processes (standing times, charging demand, etc. per vehicle), including metadata, from SimBEV.
potential_charging_points_dir (str or pathlib.PurePath) – Directory holding data on potential charging point locations from TracBEV.
import_electromobility_data_kwds (dict) –
These may contain any further attributes you want to specify when importing electromobility data.
- gc_to_car_rate_homefloat
Specifies the minimum rate between potential charging points for the use case “home” and the total number of cars. Default: 0.5.
- gc_to_car_rate_workfloat
Specifies the minimum rate between potential charging points for the use case “work” and the total number of cars. Default: 0.25.
- gc_to_car_rate_publicfloat
Specifies the minimum rate between potential charging points for the use case “public” and the total number of cars. Default: 0.1.
- gc_to_car_rate_hpcfloat
Specifies the minimum rate between potential charging points for the use case “hpc” and the total number of cars. Default: 0.005.
- mode_parking_timesstr
If the mode_parking_times is set to “frugal” only parking times with any charging demand are imported. Any other input will lead to all parking and driving events being imported. Default: “frugal”.
- charging_processes_dirstr
Charging processes sub-directory. Only used when data_source is set to “directory”. Default: None.
- simbev_config_filestr
Name of the simbev config file. Only used when data_source is set to “directory”. Default: “metadata_simbev_run.json”.
allocate_charging_demand_kwds –
These may contain any further attributes you want to specify when calling the function
distribute_charging_demand()that allocates charging processes to potential charging points.- modestr
Distribution mode. If the mode is set to “user_friendly” only the simbev weights are used for the distribution. If the mode is “grid_friendly” also grid conditions are respected. Default: “user_friendly”.
- generators_weight_factorfloat
Weighting factor of the generators weight within an LV grid in comparison to the loads weight. Default: 0.5.
- distance_weightfloat
Weighting factor for the distance between a potential charging park and its nearest substation in comparison to the combination of the generators and load factors of the LV grids. Default: 1 / 3.
- user_friendly_weightfloat
Weighting factor of the user-friendly weight in comparison to the grid friendly weight. Default: 0.5.
- apply_charging_strategy(strategy='dumb', **kwargs)[source]¶
Applies charging strategy to set EV charging time series at charging parks.
This function requires that standing times, charging demand, etc. at charging parks were previously set using
import_electromobility.It is assumed that only ‘private’ charging processes at ‘home’ or at ‘work’ can be flexibilized. ‘public’ charging processes will always be ‘dumb’.
The charging time series at each charging parks are written to
loads_active_power. Reactive power inloads_reactive_poweris set to 0 Mvar.- Parameters:
strategy (str) –
Defines the charging strategy to apply. The following charging strategies are valid:
’dumb’
The cars are charged directly after arrival with the maximum possible charging capacity.
’reduced’
The cars are charged directly after arrival with the minimum possible charging power. The minimum possible charging power is determined by the parking time and the parameter minimum_charging_capacity_factor.
’residual’
The cars are charged when the residual load in the MV grid is lowest (high generation and low consumption). Charging processes with a low flexibility are given priority.
Default: ‘dumb’.
timestamp_share_threshold (float) – Percental threshold of the time required at a time step for charging the vehicle. If the time requirement is below this limit, then the charging process is not mapped into the time series. If, however, it is above this limit, the time step is mapped to 100% into the time series. This prevents differences between the charging strategies and creates a compromise between the simultaneity of charging processes and an artificial increase in the charging demand. Default: 0.2.
minimum_charging_capacity_factor (float) – Technical minimum charging power of charging points in p.u. used in case of charging strategy ‘reduced’. E.g. for a charging point with a nominal capacity of 22 kW and a minimum_charging_capacity_factor of 0.1 this would result in a minimum charging power of 2.2 kW. Default: 0.1.
Notes
If the frequency of time series data in
TimeSeries(checked usingtimeindex) differs from the frequency of SimBEV data, then the time series inTimeSeriesis first automatically resampled to match the SimBEV data frequency and after determining the charging demand time series resampled back to the original frequency.
- import_heat_pumps(scenario, engine, timeindex=None, import_types=None)[source]¶
Gets heat pump data for specified scenario from oedb and integrates the heat pumps into the grid.
Besides heat pump capacity the heat pump’s COP and heat demand to be served are as well retrieved.
Currently, the only supported data source is scenario data generated in the research project eGo^n. You can choose between two scenarios: ‘eGon2035’ and ‘eGon100RE’.
The data is retrieved from the open energy platform.
# ToDo Add information on scenarios and from which tables data is retrieved.
The following steps are conducted in this function:
Heat pump capacities for individual and district heating per building respectively district heating area are obtained from the database for the specified scenario and integrated into the grid using the function
oedb().Heat pumps are integrated into the grid (added to
loads_df) as follows.Grid connection points of heat pumps for individual heating are determined based on the corresponding building ID. In case the heat pump is too large to use the same grid connection point, they are connected via their own grid connection point.
Grid connection points of heat pumps for district heating are determined based on their geolocation and installed capacity. See
connect_to_mvandconnect_to_lv_based_on_geolocationfor more information.
COP and heat demand for each heat pump are retrieved from the database, using the functions
cop_oedb()respectivelyheat_demand_oedb(), and stored in theHeatPumpclass that can be accessed throughheat_pump.
Be aware that this function does not yield electricity load time series for the heat pumps. The actual time series are determined through applying an operation strategy or optimising heat pump dispatch. Further, the heat pumps do not yet have a thermal storage and can therefore not yet be used as a flexibility. Thermal storage units need to be added manually to
thermal_storage_units_df.After the heat pumps are integrated there may be grid issues due to the additional load. These are not solved automatically. If you want to have a stable grid without grid issues you can invoke the automatic grid expansion through the function
reinforce.- Parameters:
scenario (str) – Scenario for which to retrieve heat pump data. Possible options are ‘eGon2035’ and ‘eGon100RE’.
engine (sqlalchemy.Engine) – Database engine.
timeindex (pandas.DatetimeIndex or None) – Specifies time steps for which to set COP and heat demand data. Leap years can currently not be handled. In case the given timeindex contains a leap year, the data will be indexed using the default year (2035 in case of the ‘eGon2035’ and to 2045 in case of the ‘eGon100RE’ scenario) and returned for the whole year. If no timeindex is provided, the timeindex set in
timeindexis used. Iftimeindexis not set, the data is indexed using the default year and returned for the whole year.import_types (list(str) or None) – Specifies which technologies to import. Possible options are “individual_heat_pumps”, “central_heat_pumps” and “central_resistive_heaters”. If None, all are imported.
- apply_heat_pump_operating_strategy(strategy='uncontrolled', heat_pump_names=None, **kwargs)[source]¶
Applies operating strategy to set electrical load time series of heat pumps.
This function requires that COP and heat demand time series, and depending on the operating strategy also information on thermal storage units, were previously set in
heat_pump. COP and heat demand information is automatically set when usingimport_heat_pumps. When not using this function it can be manually set usingset_copandset_heat_demand.The electrical load time series of each heat pump are written to
loads_active_power. Reactive power inloads_reactive_poweris set to 0 Mvar.- Parameters:
strategy (str) –
Defines the operating strategy to apply. The following strategies are valid:
’uncontrolled’
The heat demand is directly served by the heat pump without buffering heat using a thermal storage. The electrical load of the heat pump is determined as follows:
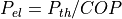
Default: ‘uncontrolled’.
heat_pump_names (list(str) or None) – Defines for which heat pumps to apply operating strategy. If None, all heat pumps for which COP information in
heat_pumpis given are used. Default: None.
- import_dsm(scenario: str, engine: sqlalchemy.engine.base.Engine, timeindex=None)[source]¶
Gets industrial and CTS DSM profiles from the OpenEnergy DataBase.
Profiles comprise minimum and maximum load increase in MW as well as maximum energy pre- and postponing in MWh. The data is written to the
DSMobject.Currently, the only supported data source is scenario data generated in the research project eGo^n. You can choose between two scenarios: ‘eGon2035’ and ‘eGon100RE’.
- Parameters:
edisgo_object (
EDisGo)scenario (str) – Scenario for which to retrieve DSM data. Possible options are ‘eGon2035’ and ‘eGon100RE’.
engine (sqlalchemy.Engine) – Database engine.
timeindex (pandas.DatetimeIndex or None) – Specifies time steps for which to get data. Leap years can currently not be handled. In case the given timeindex contains a leap year, the data will be indexed using the default year (2035 in case of the ‘eGon2035’ and to 2045 in case of the ‘eGon100RE’ scenario) and returned for the whole year. If no timeindex is provided, the timeindex set in
timeindexis used. Iftimeindexis not set, the data is indexed using the default year and returned for the whole year.
- import_home_batteries(scenario: str, engine: sqlalchemy.engine.base.Engine)[source]¶
Gets home battery data for specified scenario and integrates the batteries into the grid.
Currently, the only supported data source is scenario data generated in the research project eGo^n. You can choose between two scenarios: ‘eGon2035’ and ‘eGon100RE’.
The data is retrieved from the open energy platform.
The batteries are integrated into the grid (added to
storage_units_df) based on their building ID. In case the battery is too large to use the same grid connection point as the generator or, if no generator is allocated at the same building ID, the load, they are connected via their own grid connection point, based on their geolocation and installed capacity.Be aware that this function does not yield time series for the batteries. The actual time series can be determined through a dispatch optimisation.
- Parameters:
scenario (str) – Scenario for which to retrieve home battery data. Possible options are ‘eGon2035’ and ‘eGon100RE’.
engine (sqlalchemy.Engine) – Database engine.
- plot_mv_grid_topology(technologies=False, **kwargs)[source]¶
Plots plain MV network topology and optionally nodes by technology type (e.g. station or generator).
For more information see
edisgo.tools.plots.mv_grid_topology().- Parameters:
technologies (bool) – If True plots stations, generators, etc. in the topology in different colors. If False does not plot any nodes. Default: False.
- plot_mv_voltages(**kwargs)[source]¶
Plots voltages in MV network on network topology plot.
For more information see
edisgo.tools.plots.mv_grid_topology().
- plot_mv_line_loading(**kwargs)[source]¶
Plots relative line loading (current from power flow analysis to allowed current) of MV lines.
For more information see
edisgo.tools.plots.mv_grid_topology().
- plot_mv_grid_expansion_costs(**kwargs)[source]¶
Plots grid expansion costs per MV line.
For more information see
edisgo.tools.plots.mv_grid_topology().
- plot_mv_storage_integration(**kwargs)[source]¶
Plots storage position in MV topology of integrated storage units.
For more information see
edisgo.tools.plots.mv_grid_topology().
- plot_mv_grid(**kwargs)[source]¶
General plotting function giving all options of function
edisgo.tools.plots.mv_grid_topology().
- histogram_voltage(timestep=None, title=True, **kwargs)[source]¶
Plots histogram of voltages.
For more information on the histogram plot and possible configurations see
edisgo.tools.plots.histogram().- Parameters:
timestep (pandas.Timestamp or list(pandas.Timestamp) or None, optional) – Specifies time steps histogram is plotted for. If timestep is None all time steps voltages are calculated for are used. Default: None.
title (
strorbool, optional) – Title for plot. If True title is auto generated. If False plot has no title. Ifstr, the provided title is used. Default: True.
- histogram_relative_line_load(timestep=None, title=True, voltage_level='mv_lv', **kwargs)[source]¶
Plots histogram of relative line loads.
For more information on how the relative line load is calculated see
edisgo.tools.tools.calculate_relative_line_load(). For more information on the histogram plot and possible configurations seeedisgo.tools.plots.histogram().- Parameters:
timestep (pandas.Timestamp or list(pandas.Timestamp) or None, optional) – Specifies time step(s) histogram is plotted for. If timestep is None all time steps currents are calculated for are used. Default: None.
title (
strorbool, optional) – Title for plot. If True title is auto generated. If False plot has no title. Ifstr, the provided title is used. Default: True.voltage_level (
str) – Specifies which voltage level to plot voltage histogram for. Possible options are ‘mv’, ‘lv’ and ‘mv_lv’. ‘mv_lv’ is also the fallback option in case of wrong input. Default: ‘mv_lv’
- save(directory, save_topology=True, save_timeseries=True, save_results=True, save_electromobility=False, save_opf_results=False, save_heatpump=False, save_overlying_grid=False, save_dsm=False, **kwargs)[source]¶
Saves EDisGo object to csv files.
It can be chosen what is included in the csv export (e.g. power flow results, electromobility flexibility, etc.). Further, in order to save disk storage space the data type of time series data can be reduced, e.g. to float32 and data can be archived, e.g. in a zip archive.
- Parameters:
directory (str) – Main directory to save EDisGo object to.
save_topology (bool, optional) – Indicates whether to save
Topologyobject. Per default, it is saved to sub-directory ‘topology’. Seeto_csvfor more information. Default: True.save_timeseries (bool, optional) – Indicates whether to save
TimeSeriesobject. Per default it is saved to subdirectory ‘timeseries’. Through the keyword arguments reduce_memory and to_type it can be chosen if memory should be reduced. Seeto_csvfor more information. Default: True.save_results (bool, optional) – Indicates whether to save
Resultsobject. Per default, it is saved to subdirectory ‘results’. Through the keyword argument parameters the results that should be stored can be specified. Further, through the keyword parameters reduce_memory and to_type it can be chosen if memory should be reduced. Seeto_csvfor more information. Default: True.save_electromobility (bool, optional) – Indicates whether to save
Electromobilityobject. Per default, it is not saved. If set to True, it is saved to subdirectory ‘electromobility’. Seeto_csvfor more information.save_opf_results (bool, optional) – Indicates whether to save
OPFResultsobject. Per default, it is not saved. If set to True, it is saved to subdirectory ‘opf_results’. Seeto_csvfor more information.save_heatpump (bool, optional) – Indicates whether to save
HeatPumpobject. Per default, it is not saved. If set to True, it is saved to subdirectory ‘heat_pump’. Seeto_csvfor more information.save_overlying_grid (bool, optional) – Indicates whether to save
OverlyingGridobject. Per default, it is not saved. If set to True, it is saved to subdirectory ‘overlying_grid’. Seeto_csvfor more information.save_dsm (bool, optional) – Indicates whether to save
DSMobject. Per default, it is not saved. If set to True, it is saved to subdirectory ‘dsm’. Seeto_csvfor more information.reduce_memory (bool, optional) – If True, size of dataframes containing time series in
Results,TimeSeries,HeatPump,OverlyingGridandDSMis reduced. See respective classes reduce_memory functions for more information. Type to convert to can be specified by providing to_type as keyword argument. Further parameters of reduce_memory functions cannot be passed here. Call these functions directly to make use of further options. Default: False.to_type (str, optional) – Data type to convert time series data to. This is a trade-off between precision and memory. Default: “float32”.
parameters (None or dict) – Specifies which results to store. By default, this is set to None, in which case all available results are stored. To only store certain results provide a dictionary. See function docstring parameters parameter in
to_csvfor more information.electromobility_attributes (None or list(str)) – Specifies which electromobility attributes to store. By default, this is set to None, in which case all attributes are stored. See function docstring attributes parameter in
to_csvfor more information.archive (bool, optional) – Save disk storage capacity by archiving the csv files. The archiving takes place after the generation of the CSVs and therefore temporarily the storage needs are higher. Default: False.
archive_type (str, optional) – Set archive type. Default: “zip”.
drop_unarchived (bool, optional) – Drop the unarchived data if parameter archive is set to True. Default: True.
- save_edisgo_to_json(filename=None, path='', s_base=1, flexible_cps=None, flexible_hps=None, flexible_loads=None, flexible_storage_units=None, opf_version=1)[source]¶
Saves EDisGo object in PowerModels network data format to json file.
- Parameters:
filename (str or None) – Filename the json file is saved under. If None, filename is ‘ding0_{grid_id}_t_{#timesteps}.json’.
path (str) – Directory the json file is saved to. Per default, it takes the current working directory.
s_base (int) – Base value of apparent power for per unit system. Default: 1 MVA
flexible_cps (numpy.ndarray or None) – Array containing all charging points that allow for flexible charging.
flexible_hps (numpy.ndarray or None) – Array containing all heat pumps that allow for flexible operation due to an attached heat storage.
flexible_loads (numpy.ndarray or None) – Array containing all flexible loads that allow for application of demand side management strategy.
flexible_storage_units (numpy.ndarray or None) – Array containing all flexible storages. Non-flexible storages operate to optimize self consumption. Default: None
opf_version (Int) – Version of optimization models to choose from. Must be one of [1, 2, 3, 4]. For more information see
edisgo.opf.powermodels_opf.pm_optimize(). Default: 1.
- Returns:
Dictionary that contains all network data in PowerModels network data format.
- Return type:
- reduce_memory(**kwargs)[source]¶
Reduces size of time series data to save memory.
Per default, float data is stored as float64. As this precision is barely needed, this function can be used to convert time series data to a data subtype with less memory usage, such as float32.
- Parameters:
to_type (str, optional) – Data type to convert time series data to. This is a tradeoff between precision and memory. Default: “float32”.
results_attr_to_reduce (list(str), optional) – See attr_to_reduce parameter in
reduce_memoryfor more information.timeseries_attr_to_reduce (list(str), optional) – See attr_to_reduce parameter in
reduce_memoryfor more information.heat_pump_attr_to_reduce (list(str), optional) – See attr_to_reduce parameter in
reduce_memoryfor more information.overlying_grid_attr_to_reduce (list(str), optional) – See attr_to_reduce parameter in
reduce_memoryfor more information.dsm_attr_to_reduce (list(str), optional) – See attr_to_reduce parameter in
reduce_memoryfor more information.
- spatial_complexity_reduction(copy_edisgo: bool = False, mode: str = 'kmeansdijkstra', cluster_area: str = 'feeder', reduction_factor: float = 0.25, reduction_factor_not_focused: bool | float = False, apply_pseudo_coordinates: bool = True, **kwargs) tuple[EDisGo, pandas.DataFrame, pandas.DataFrame][source]¶
Reduces the number of busses and lines by applying a spatial clustering.
Per default, this function creates pseudo coordinates for all busses in the LV grids (see function
make_pseudo_coordinates()). In case LV grids are not geo-referenced, this is a necessary step. If they are already geo-referenced it can still be useful to obtain better results.Which busses are clustered is determined in function
make_busmap(). The clustering method used can be specified through the parameter mode. Further, the clustering can be applied to different areas such as the whole grid or the separate feeders, which is specified through the parameter cluster_area, and to different degrees, specified through the parameter reduction_factor.The actual spatial reduction of the EDisGo object is conducted in function
apply_busmap(). The changes, such as dropping of lines connecting the same buses and adapting buses loads, generators and storage units are connected to, are applied directly in the Topology object. If you want to keep information on the original grid, hand a copy of the EDisGo object to this function. You can also set how loads and generators at clustered busses are aggregated through the keyword arguments load_aggregation_mode and generator_aggregation_mode.- Parameters:
copy_edisgo (bool) – Defines whether to apply the spatial complexity reduction directly on the EDisGo object or on a copy. Per default, the complexity reduction is directly applied.
mode (str) –
Clustering method to use. Possible options are “kmeans”, “kmeansdijkstra”, “aggregate_to_main_feeder” or “equidistant_nodes”. The clustering methods “aggregate_to_main_feeder” and “equidistant_nodes” only work for the cluster area “main_feeder”.
- ”kmeans”:
Perform the k-means algorithm on the cluster area and then map the buses to the cluster centers.
- ”kmeansdijkstra”:
Perform the k-means algorithm and then map the nodes to the cluster centers through the shortest distance in the graph. The distances are calculated using the dijkstra algorithm.
- ”aggregate_to_main_feeder”:
Aggregate the nodes in the feeder to the longest path in the feeder, here called main feeder.
- ”equidistant_nodes”:
Uses the method “aggregate_to_main_feeder” and then reduces the nodes again through a reduction of the nodes by the specified reduction factor and distributing the remaining nodes on the graph equidistantly.
Default: “kmeansdijkstra”.
cluster_area (str) – The cluster area is the area the different clustering methods are applied to. Possible options are ‘grid’, ‘feeder’ or ‘main_feeder’. Default: “feeder”.
reduction_factor (float) – Factor to reduce number of nodes by. Must be between 0 and 1. Default: 0.25.
reduction_factor_not_focused (bool or float) – If False, uses the same reduction factor for all cluster areas. If between 0 and 1, this sets the reduction factor for buses not of interest (these are buses without voltage or overloading issues, that are determined through a worst case power flow analysis). When selecting 0, the nodes of the clustering area are aggregated to the transformer bus. This parameter is only used when parameter cluster_area is set to ‘feeder’ or ‘main_feeder’. Default: False.
apply_pseudo_coordinates (bool) – If True pseudo coordinates are applied. The spatial complexity reduction method is only tested with pseudo coordinates. Default: True.
line_naming_convention (str) – Determines how to set “type_info” and “kind” in case two or more lines are aggregated. Possible options are “standard_lines” or “combined_name”. If “standard_lines” is selected, the values of the standard line of the respective voltage level are used to set “type_info” and “kind”. If “combined_name” is selected, “type_info” and “kind” contain the concatenated values of the merged lines. x and r of the lines are not influenced by this as they are always determined from the x and r values of the aggregated lines. Default: “standard_lines”.
aggregation_mode (bool) – Specifies, whether to aggregate loads and generators at the same bus or not. If True, loads and generators at the same bus are aggregated according to their selected modes (see parameters load_aggregation_mode and generator_aggregation_mode). Default: False.
load_aggregation_mode (str) – Specifies, how to aggregate loads at the same bus, in case parameter aggregation_mode is set to True. Possible options are “bus” or “sector”. If “bus” is chosen, loads are aggregated per bus. When “sector” is chosen, loads are aggregated by bus, type and sector. Default: “sector”.
generator_aggregation_mode (str) – Specifies, how to aggregate generators at the same bus, in case parameter aggregation_mode is set to True. Possible options are “bus” or “type”. If “bus” is chosen, generators are aggregated per bus. When “type” is chosen, generators are aggregated by bus and type.
mv_pseudo_coordinates (bool, optional) – If True pseudo coordinates are also generated for MV grid. Default: False.
- Returns:
Returns the EDisGo object (which is only relevant in case the parameter copy_edisgo was set to True), as well as the busmap and linemap dataframes. The busmap maps the original busses to the new busses with new coordinates. Columns are “new_bus” with new bus name, “new_x” with new x-coordinate and “new_y” with new y-coordinate. Index of the dataframe holds bus names of original buses as in buses_df. The linemap maps the original line names (in the index of the dataframe) to the new line names (in column “new_line_name”).
- Return type:
tuple(
EDisGo, pandas.DataFrame, pandas.DataFrame)
- check_integrity()[source]¶
Method to check the integrity of the EDisGo object.
Checks for consistency of topology (see
edisgo.network.topology.Topology.check_integrity()), timeseries (seeedisgo.network.timeseries.TimeSeries.check_integrity()) and the interplay of both. Further, checks integrity of electromobility object (seeedisgo.network.electromobility.Electromobility.check_integrity()), the heat pump object (seeedisgo.network.heat.HeatPump.check_integrity()) and the DSM object (seeedisgo.network.dsm.DSM.check_integrity()). Additionally, checks whether time series data inHeatPump,Electromobility,OverlyingGridandDSMcontains all time steps inedisgo.network.timeseries.TimeSeries.timeindex.
- resample_timeseries(method: str = 'ffill', freq: str | pandas.Timedelta = '15min')[source]¶
Resamples time series data in
TimeSeries,HeatPump,ElectromobilityandOverlyingGrid.Both up- and down-sampling methods are possible.
The following time series are affected by this:
All data in
OverlyingGrid
- Parameters:
method (str, optional) –
Method to choose from to fill missing values when resampling time series data (only exception from this is for flexibility bands in
Electromobilityobject where method cannot be chosen to assure consistency of flexibility band data). Possible options are:- ’ffill’ (default)
Propagate last valid observation forward to next valid observation. See pandas.DataFrame.ffill.
- ’bfill’
Use next valid observation to fill gap. See pandas.DataFrame.bfill.
- ’interpolate’
Fill NaN values using an interpolation method. See pandas.DataFrame.interpolate.
Default: ‘ffill’.
freq (str, optional) – Frequency that time series is resampled to. Offset aliases can be found here: https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#offset-aliases. Default: ‘15min’.
- edisgo.edisgo.import_edisgo_from_pickle(filename, path='')[source]¶
Restores EDisGo object from pickle file.
- edisgo.edisgo.import_edisgo_from_files(edisgo_path: str | pathlib.PurePath, import_topology: bool = True, import_timeseries: bool = False, import_results: bool = False, import_electromobility: bool = False, import_opf_results: bool = False, import_heat_pump: bool = False, import_dsm: bool = False, import_overlying_grid: bool = False, from_zip_archive: bool = False, **kwargs)[source]¶
Sets up EDisGo object from csv files.
This is the reverse function of
saveand if not specified differently assumes all data in the default sub-directories created in thesavefunction.- Parameters:
edisgo_path (str or pathlib.PurePath) – Main directory to restore EDisGo object from. This directory must contain the config files. Further, if not specified differently, it is assumed to be the main directory containing sub-directories with e.g. topology data. In case from_zip_archive is set to True, edisgo_path is the name of the archive.
import_topology (bool) – Indicates whether to import
Topologyobject. Per default, it is set to True, in which case topology data is imported. The default directory topology data is imported from is the sub-directory ‘topology’. A different directory can be specified through keyword argument topology_directory. Default: True.import_timeseries (bool) – Indicates whether to import
TimeSeriesobject. Per default, it is set to False, in which case timeseries data is not imported. The default directory time series data is imported from is the sub-directory ‘timeseries’. A different directory can be specified through keyword argument timeseries_directory. Default: False.import_results (bool) – Indicates whether to import
Resultsobject. Per default, it is set to False, in which case results data is not imported. The default directory results data is imported from is the sub-directory ‘results’. A different directory can be specified through keyword argument results_directory. Default: False.import_electromobility (bool) – Indicates whether to import
Electromobilityobject. Per default, it is set to False, in which case electromobility data is not imported. The default directory electromobility data is imported from is the sub-directory ‘electromobility’. A different directory can be specified through keyword argument electromobility_directory. Default: False.import_opf_results (bool) – Indicates whether to import
OPFResultsobject. Per default, it is set to False, in which case opf results data is not imported. The default directory results data is imported from is the sub-directory ‘opf_results’. A different directory can be specified through keyword argument opf_results_directory. Default: False.import_heat_pump (bool) – Indicates whether to import
HeatPumpobject. Per default, it is set to False, in which case heat pump data containing information on COP, heat demand time series, etc. is not imported. The default directory heat pump data is imported from is the sub-directory ‘heat_pump’. A different directory can be specified through keyword argument heat_pump_directory. Default: False.import_overlying_grid (bool) – Indicates whether to import
OverlyingGridobject. Per default, it is set to False, in which case overlying grid data containing information on renewables curtailment requirements, generator dispatch, etc. is not imported. The default directory overlying grid data is imported from is the sub-directory ‘overlying_grid’. A different directory can be specified through keyword argument overlying_grid_directory. Default: False.import_dsm (bool) – Indicates whether to import
DSMobject. Per default, it is set to False, in which case DSM data is not imported. The default directory DSM data is imported from is the sub-directory ‘dsm’. A different directory can be specified through keyword argument dsm_directory. Default: False.from_zip_archive (bool) – Set to True if data needs to be imported from an archive, e.g. a zip archive. Default: False.
topology_directory (str) – Indicates directory
Topologyobject is imported from. Per default, topology data is imported from edisgo_path sub-directory ‘topology’.timeseries_directory (str) – Indicates directory
TimeSeriesobject is imported from. Per default, time series data is imported from edisgo_path sub-directory ‘timeseries’.results_directory (str) – Indicates directory
Resultsobject is imported from. Per default, results data is imported from edisgo_path sub-directory ‘results’.electromobility_directory (str) – Indicates directory
Electromobilityobject is imported from. Per default, electromobility data is imported from edisgo_path sub-directory ‘electromobility’.opf_results_directory (str) – Indicates directory
OPFResultsobject is imported from. Per default, results data is imported from edisgo_path sub-directory ‘opf_results’.heat_pump_directory (str) – Indicates directory
HeatPumpobject is imported from. Per default, heat pump data is imported from edisgo_path sub-directory ‘heat_pump’.overlying_grid_directory (str) – Indicates directory
OverlyingGridobject is imported from. Per default, overlying grid data is imported from edisgo_path sub-directory ‘overlying_grid’.dsm_directory (str) – Indicates directory
DSMobject is imported from. Per default, DSM data is imported from edisgo_path sub-directory ‘dsm’.dtype (str) – Numerical data type for time series and results data to be imported, e.g. “float32”. Per default, this is None in which case data type is inferred.
parameters (None or dict) – Specifies which results to restore. By default, this is set to None, in which case all available results are restored. To only restore certain results provide a dictionary. See function docstring parameters parameter in
to_csv()for more information.
- Returns:
Restored EDisGo object.
- Return type: